|
|
| Levels of availability
First of all, availability is closely related to cost, as shown in Figure 8-1. It is important to balance the downtime with cost. The more you invest, the less downtime there is. Therefore, it is also very important for you to evaluate what you will lose if your WebSphere service is temporarily unavailable. Different businesses have different costs for downtime, and some businesses such as financial services may lose millions of dollars for each hour of downtime during business hours. Costs for the downtime include not only direct dollar losses but also reputation and customer relationships losses.
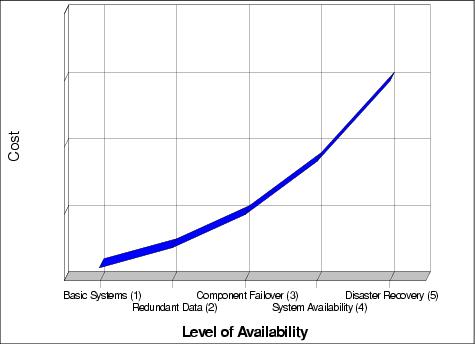
Figure 8-1 Levels of availability and costs
As we discussed above, redundant hardware and clustering software are approaches to high availability. We can divide availability into the following levels:
|
| 1.
| Basic systems. Basic systems do not employ any special measures to protect data and services, although backups are taken regularly. When an outage occurs, the support personnel restores the system from backup (usually tape).
|
| 2.
| Redundant data. Disk redundancy and/or disk mirroring are used to protect the data against the loss of a disk. Full disk mirroring provides more data protection than RAID-5.
|
| 3.
| Component failover. For an e-business infrastructure like WebSphere, there are many components. As we discussed above, an outage in any component may result in service interruption. Multiple threads or multiple instances can be employed for availability purposes. For example, if we do not make the firewall component highly available, it may cause the whole system to go down (worse than that, it may expose your system to hackers) even though the servers are highly available.
For WebSphere, we have process high availability (vertical scaling) and process and node high availability (horizontal scaling). Entity EJBs are persisted into the database. Highly available data management is critical for a highly available transactional system. Therefore, it is very important to balance the availability of all components in the WebSphere production system. Do not overspend on any particular component, and do not underspend on other components, either. For example, for the system shown in Figure 8-2, the system availability seen by the client would be 85%.
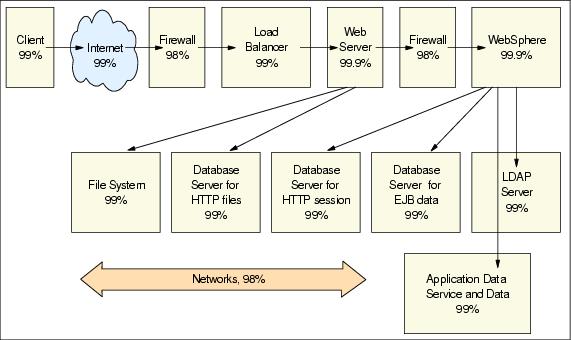
Figure 8-2 Availability chains
|
| 4.
| System failover. A standby or backup system is used to take over for the primary system if the primary system fails. In principle, any kind of service can become highly available by employing system failover techniques. However, this will not work if the software is hard-coded to physical host-dependent variables. We can configure the systems as active/active mutual takeover or active/standby takeover. Although the active/active mutual takeover configuration increases the usage of hardware, it also increases the possibility of interruption, and hence reduces the availability. In addition, it is not efficient to include all components into a single cluster system. We have a firewall cluster, LDAP cluster, WebSphere server cluster, and database cluster. In system failover, clustering software monitors the health of the network, hardware, and software process, detects and communicates any fault, and automatically fails over the service and associated resources to a healthy host. Therefore, you can continue the service before you repair the failed system. As we discussed before, as MTTR approaches zero, A increases toward 100%. System failover can also be used for planned software and hardware maintenance and upgrades.
|
| 5.
| Disaster recovery. This applies to maintaining systems in different sites. When the primary site becomes unavailable due to disasters, the backup site can become operational within a reasonable time. This can be done manually through regular data backups, or automatically by geographical clustering software.
Continuous availability means that high availability and continuous operations are required to eliminate all planned downtime.
Different customers have different availability requirements and downtime costs. For example, one hour of downtime can cost millions of dollars for brokerage firms, but only tens of thousands of dollars for transportation firms. Furthermore, system availability is determined by the weakest point in the WebSphere production environment.
|
|
Prev | Home | Next
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both. IBM is a trademark of the IBM Corporation in the United States, other countries, or both. |