Failover
There are a number of situations when the plug-in might not be able to complete a request to an appserver. In a clustered environment with several cluster members this does not need to interrupt service.
Here are some example situations when the plug-in cannot connect to a cluster member:
| The cluster member has been brought down intentionally for maintenance. |
| The appserver crashes. |
| There is a network problem between the plug-in and the cluster member. |
| The cluster member is overloaded and cannot process the request. |
When the plug-in has selected a cluster member to handle a request (see Figure 5-7, boxes 7,8 and 9), it will attempt to communicate with the cluster member. If this communication is unsuccessful or breaks, then the plug-in will mark the cluster member as down and attempt to find another cluster member to handle the request.
The marking of the cluster member as down means that, should that cluster member be chosen as part of a workload management policy or in session affinity, the plug-in will not try to connect to it. The plug-in will see that it is marked as down and ignore it.
The plug-in will wait for a period of time before removing the marked as down status from the cluster member. This period of time is called the retry interval. By default, the retry interval is 60 seconds. If you turn on tracing in the plug-in log file, it is possible to see how long is left until the cluster member will be tried again.
To set RetryInterval, edit the plugin-cfg.xml file and locate the ServerCluster tag for the required server cluster. The value can be any integer. Below is an example of this:
<ServerCluster CloneSeparatorChange="false" LoadBalance="Round Robin" Name="PluginCluster" PostSizeLimit="-1" RemoveSpecialHeaders="true" RetryInterval="10">
This sets the RetryInterval to 10 seconds. If a downed cluster member in this server cluster is selected for a request, and 10 seconds have elapsed since the last attempt, the plug-in will try again to connect to it.
By marking the cluster member as down, the plug-in does not spend time at every request attempting to connect to it again. It will continue using other available cluster members without retrying the down cluster member, until the retry interval has elapsed.
Figure 5-10 shows how this selection process works. It is an expansion of box 8 from Figure 5-7.
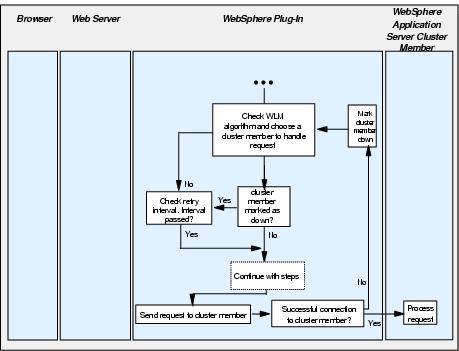
Figure 5-10 Failover selection process
Note: For more information about failover, go to 5.7, Web server plug-in behavior and failover. It runs through some examples of what happens in a failover situation. |
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both.
IBM is a trademark of the IBM Corporation in the United States, other countries, or both.