XSLT
Overview
The XML Stylesheet Language for Transformations (XSLT) allows one to perform transforms on the structure and content of XML documents.
JAXP includes an interpreter version of XSLT (Xalan), and a compiler version (XSLTC). The compiled version saves versions of transformations into translets, and runs much faster than the interpreted version.
The JAXP Transformation APIs include:
- javax.xml.transform
- Defines the factory class you use to get a Transformer object. You then configure the transformer with input (Source) and output (Result) objects, and invoke its transform() method to make the transformation happen. The source and result objects are created using classes from one of the other three packages.
- javax.xml.transform.dom
- Defines the DOMSource and DOMResult classes that let you use a DOM as an input to or output from a transformation.
- javax.xml.transform.sax
- Defines the SAXSource and SAXResult classes that let you use a SAX event generator as input to a transformation, or deliver SAX events as output to a SAX event processor.
- javax.xml.transform.stream
- Defines the StreamSource and StreamResult classes that let you use an I/O stream as an input to or output from a transformation.
Transforming XML into HTML
article1a.xsl transforms article1.xml into HTML.
The hierarchical structure of an XML file constitutes the source tree. The output we obtain using the XSLT transform creates a result tree.
Define an XSL stylesheet
Put something like the following lines into: filename.xsl
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0" >
</xsl:stylesheet>
Output Methods
Options for the output method include: "xml", "html", or "text", with the default output method being "xml". The following highlighted line produces HTML-compatible output.<xsl:stylesheet> <xsl:output method="html"/> </xsl:stylesheet>
indent
To produce nicely indented XML output, use the indent attribute:
<xsl:output method="xml" indent="yes"/>.
xsl:template
The <xsl:template> tag defines a template. Each template contains a match attribute, which selects the elements that the template will be applied to, using XPath addressing.In the following example, when the TITLE element path is matched, HTML is created that centers the title text within an h1 element.
<xsl:template match="/ARTICLE/TITLE">
<h1 align="center"> <xsl:apply-templates/> </h1>
</xsl:template>
The apply-templates tag ensures that, in addition to text, if the title contains any inline tags such as italics, links, or underlining, they will be processed as well.
When a newline is not present, whitespace is generally ignored. To include whitespace in the output use the <xsl:text> tag.
"select" Clause
The select= clause applies templates to a subset of the information available in the current context.
<xsl:template match="/ARTICLE/SECT">
<h2>
<xsl:apply-templates select="text()|B|I|U|DEF|LINK"/>
</h2>
<xsl:apply-templates select="SECT|PARA|LIST|NOTE"/>
</xsl:template>
The first select= above selects inline elements, as well as the XPath text() function. The second selects structure elements, including sections, paragraphs, lists, and notes.
The result is that all the text and inline elements in the section are placed between the <h2>...</h2> tags, while all structure tags in the section are processed afterwards.
To process subheadings that are nested one level deeper:
<xsl:template match="/ARTICLE/SECT/SECT">
<h3> <xsl:apply-templates
select="text()|B|I|U|DEF|LINK"/> </h3>
<xsl:apply-templates select="SECT|PARA|LIST|NOTE"/>
</xsl:template>
terminate Clause
The terminate="yes" clause causes the transformation process to stop after the message is generated. Without it, processing would still go on with everything in that section being ignored.
To generate an error when a section is encountered that is nested too deep:
<xsl:template match="/ARTICLE/SECT/SECT/SECT">
<xsl:message terminate="yes">
Error: Sections can only be nested 2 deep.
</xsl:message>
</xsl:template>
Write the Basic Program
The code required to execute the above transformation is Stylizer.java. The result of running the code can be found in stylizer1a.html.
Stylizer.java uses the source file to create a StreamSource object, and then passes the source object to the factory class to get the transformer.
DocumentBuilder builder = factory.newDocumentBuilder(); document = builder.parse(fdatafile); ... StreamSource stylesource = new StreamSource(stylesheet); Transformer transformer = Factory.newTransformer(stylesource); ...
Compile and run the program using article1a.xsl on article1.xml.
Trim the Whitespace
If you recall, when you took a look at the structure of a DOM, there were many text nodes that contained nothing but ignorable whitespace. Most of the excess whitespace in the output came from these nodes. Fortunately, XSL gives you a way to eliminate them. (For more about the node structure, see The XSLT/XPath Data Model.)
The stylesheet described here is article1b.xsl. The result is stylizer1b.html. (The browser-displayable versions are article1b.xsl.html and stylizer1b-src.html.)
To remove some of the excess whitespace, add the line highlighted below to the stylesheet.
<xsl:stylesheet ... > <xsl:output method="html"/> <xsl:strip-space elements="SECT"/> ...
This instruction tells XSL to remove any text nodes under SECT elements that contain nothing but whitespace. Nodes that contain text other than whitespace will not be affected, and other kinds of nodes are not affected.
Now, when you run the program, the result looks like this:
<html>
<body>
<h1 align="center">A Sample Article</h1>
<h2>The First Major Section
</h2>
<p>This section will introduce a subsection.</p>
<h3>The Subsection Heading
</h3>
<p>This is the text of the subsection.
</p>
</body>
</html>
That's quite an improvement. There are still newline characters and white space after the headings, but those come from the way the XML is written:
<SECT>The First Major Section ____<PARA>This section will introduce a subsection.</PARA> ^^^^
Here, you can see that the section heading ends with a newline and indentation space, before the PARA entry starts. That's not a big worry, because the browsers that will process the HTML routinely compress and ignore the excess space. But there is still one more formatting tool at our disposal.
The stylesheet described here is article1c.xsl. The result is stylizer1c.html. (The browser-displayable versions are article1c.xsl.html and stylizer1c-src.html.)
To get rid of that last little bit of whitespace, add this template to the stylesheet:
<xsl:template match="text()">
<xsl:value-of select="normalize-space()"/>
</xsl:template>
</xsl:stylesheet>
The output now looks like this:
<html> <body> <h1 align="center">A Sample Article</h1> <h2>The First Major Section</h2> <p>This section will introduce a subsection.</p> <h3>The Subsection Heading</h3> <p>This is the text of the subsection.</p> </body> </html>
That is quite a bit better. Of course, it would be nicer if it were indented, but that turns out to be somewhat harder than expected! Here are some possible avenues of attack, along with the difficulties:
- Indent option
- Unfortunately, the indent="yes" option that can be applied to XML output is not available for HTML output. Even if that option were available, it wouldn't help, because HTML elements are rarely nested! Although HTML source is frequently indented to show the implied structure, the HTML tags themselves are not nested in a way that creates a real structure.
- Indent variables
- The <xsl:text> function lets you add any text you want, including whitespace. So, it could conceivably be used to output indentation space. The problem is to vary the amount of indentation space. XSLT variables seem like a good idea, but they don't work here. The reason is that when you assign a value to a variable in a template, the value is only known within that template (statically, at compile time value). Even if the variable is defined globally, the assigned value is not stored in a way that lets it be dynamically known by other templates at runtime. Once <apply-templates/> invokes other templates, they are unaware of any variable settings made in other templates.
- Parameterized templates
- Using a "parameterized template" is another way to modify a template's behavior. But determining the amount of indentation space to pass as the parameter remains the crux of the problem!
At the moment, then, there does not appear to be any good way to control the indentation of HTML-formatted output. That would be inconvenient if you needed to display or edit the HTML as plain text. But it's not a problem if you do your editing on the XML form, only use the HTML version for display in a browser. (When you view stylizer1c.html, for example, you see the results you expect.)
In this section, you'll process the LIST and NOTE elements that add additional structure to an article.
The sample document described in this section is article2.xml, and the stylesheet used to manipulate it is article2.xsl. The result is stylizer2.html. (The browser-displayable versions are article2.xml.html, article2.xsl.html, and stylizer2-src.html.)
Start by adding some test data to the sample document:
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
...
</SECT>
<SECT>The Second Major Section
<PARA>This section adds a LIST and a NOTE.
<PARA>Here is the LIST:
<LIST type="ordered">
<ITEM>Pears</ITEM>
<ITEM>Grapes</ITEM>
</LIST>
</PARA>
<PARA>And here is the NOTE:
<NOTE>Don't forget to go to the hardware store
on your way to the grocery!
</NOTE>
</PARA>
</SECT>
</ARTICLE>
Although the list and note in the XML file are contained in their respective paragraphs, it really makes no difference whether they are contained or not--the generated HTML will be the same, either way. But having them contained will make them easier to deal with in an outline-oriented editor.
Modify <PARA> handling
Next, modify the PARA template to account for the fact that we are now allowing some of the structure elements to be embedded with a paragraph:
<xsl:template match="PARA"><p><xsl:apply-templates/></p><p> <xsl:apply-templates select="text()|B|I|U|DEF|LINK"/> </p> <xsl:apply-templates select="PARA|LIST|NOTE"/> </xsl:template>
This modification uses the same technique you used for section headings. The only difference is that SECT elements are not expected within a paragraph. (However, a paragraph could easily exist inside another paragraph, as quoted material, for example.)
Process <LIST> and <ITEM> elements
Now you're ready to add a template to process LIST elements:
<xsl:template match="LIST"> <xsl:if test="@type='ordered'"> <ol> <xsl:apply-templates/> </ol> </xsl:if> <xsl:if test="@type='unordered'"> <ul> <xsl:apply-templates/> </ul> </xsl:if> </xsl:template> </xsl:stylesheet>
The <xsl:if> tag uses the test="" attribute to specify a boolean condition. In this case, the value of the type attribute is tested, and the list that is generated changes depending on whether the value is ordered or unordered.
The two important things to note for this example are:
- There is no else clause, nor is there a return or exit statement, so it takes two <xsl:if> tags to cover the two options. (Or the <xsl:choose> tag could have been used, which provides case-statement functionality.)
- Single quotes are required around the attribute values. Otherwise, the XSLT processor attempts to interpret the word ordered as an XPath function, instead of as a string.
Now finish up LIST processing by handling ITEM elements:
<xsl:template match="ITEM"> <li><xsl:apply-templates/> </li> </xsl:template> </xsl:stylesheet>
Ordering Templates in a Stylesheet
By now, you should have the idea that templates are independent of one another, so it doesn't generally matter where they occur in a file. So from here on, we'll just show the template you need to add. (For the sake of comparison, they're always added at the end of the example stylesheet.)
Order does make a difference when two templates can apply to the same node. In that case, the one that is defined last is the one that is found and processed. For example, to change the ordering of an indented list to use lowercase alphabetics, you could specify a template pattern that looks like this: //LIST//LIST. In that template, you would use the HTML option to generate an alphabetic enumeration, instead of a numeric one.
But such an element could also be identified by the pattern //LIST. To make sure the proper processing is done, the template that specifies //LIST would have to appear before the template the specifies //LIST//LIST.
Process <NOTE> Elements
The last remaining structure element is the NOTE element. Add the template shown below to handle that.
<xsl:template match="NOTE"> <blockquote><b>Note:</b><br/> <xsl:apply-templates/> </p></blockquote> </xsl:template> </xsl:stylesheet>
This code brings up an interesting issue that results from the inclusion of the <br/> tag. To be well-formed XML, the tag must be specified in the stylesheet as <br/>, but that tag is not recognized by many browsers. And while most browsers recognize the sequence <br></br>, they all treat it like a paragraph break, instead of a single line break.
In other words, the transformation must generate a <br> tag, but the stylesheet must specify <br/>. That brings us to the major reason for that special output tag we added early in the stylesheet:
<xsl:stylesheet ... > <xsl:output method="html"/> ... </xsl:stylesheet>
That output specification converts empty tags like <br/> to their HTML form, <br>, on output. That conversion is important, because most browsers do not recognize the empty tags. Here is a list of the affected tags:
area frame isindex base hr link basefont img meta br input param col
To summarize, by default XSLT produces well-formed XML on output. And since an XSL stylesheet is well-formed XML to start with, you cannot easily put a tag like <br> in the middle of it. The "<xsl:output method="html"/>" solves the problem, so you can code <br/> in the stylesheet, but get <br> in the output.
The other major reason for specifying <xsl:output method="html"/> is that, as with the specification <xsl:output method="text"/>, generated text is not escaped. For example, if the stylesheet includes the < entity reference, it will appear as the < character in the generated text. When XML is generated, on the other hand, the < entity reference in the stylesheet would be unchanged, so it would appear as < in the generated text.
If you actually want < to be generated as part of the HTML output, you'll need to encode it as &lt;--that sequence becomes < on output, because only the & is converted to an & character.
Run the Program
Here is the HTML that is generated for the second section when you run the program now:
... <h2>The Second Major Section</h2> <p>This section adds a LIST and a NOTE.</p> <p>Here is the LIST:</p> <ol> <li>Pears</li> <li>Grapes</li> </ol> <p>And here is the NOTE:</p> <blockquote> <b>Note:</b> <br>Don't forget to go to the hardware store on your way to the grocery! </blockquote>
The only remaining tags in the ARTICLE type are the inline tags -- the ones that don't create a line break in the output, but which instead are integrated into the stream of text they are part of.
Inline elements are different from structure elements, in that they are part of the content of a tag. If you think of an element as a node in a document tree, then each node has both content and structure. The content is composed of the text and inline tags it contains. The structure consists of the other elements (structure elements) under the tag.
The sample document described in this section is article3.xml, and the stylesheet used to manipulate it is article3.xsl. The result is stylizer3.html. (The browser-displayable versions are article3.xml.html, article3.xsl.html, and stylizer3-src.html.)
Start by adding one more bit of test data to the sample document:
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
...
</SECT>
<SECT>The Second Major Section
...
</SECT>
<SECT>The <I>Third</I> Major Section
<PARA>In addition to the inline tag in the heading,
this section defines the term <DEF>inline</DEF>,
which literally means "no line break". It also
adds a simple link to the main page for the Java
platform (<LINK>http://java.sun.com</LINK>),
as well as a link to the
<LINK target="http://java.sun.com/xml">XML</LINK>
page.
</PARA>
</SECT>
</ARTICLE>
Now, process the inline <DEF> elements in paragraphs, renaming them to HTML italics tags:
<xsl:template match="DEF"> <i> <xsl:apply-templates/> </i> </xsl:template>
Next, comment out the text-node normalization. It has served its purpose, and now you're to the point that you need to preserve important spaces:
<!-- <xsl:template match="text()"> <xsl:value-of select="normalize-space()"/> </xsl:template> -->
This modification keeps us from losing spaces before tags like <I> and <DEF>. (Try the program without this modification to see the result.)
Now, process basic inline HTML elements like <B>, <I>, <U> for bold, italics, and underlining.
<xsl:template match="B|I|U"> <xsl:element name="{name()}"> <xsl:apply-templates/> </xsl:element> </xsl:template>
The <xsl:element> tag lets you compute the element you want to generate. Here, you generate the appropriate inline tag using the name of the current element. In particular, note the use of curly braces ({}) in the name=".." expression. Those curly braces cause the text inside the quotes to be processed as an XPath expression, instead of being interpreted as a literal string. Here, they cause the XPath name() function to return the name of the current node.
Curly braces are recognized anywhere that an attribute value template can occur. Attribute(value templates are defined in section 7.6.2 of the XSLT specification, and they appear several places in the template definitions.). In such expressions, curly braces can also be used to refer to the value of an attribute, {@foo}, or to the content of an element {foo}.
You can also generate attributes using <xsl:attribute>. For more information, see Section 7.1.3 of the XSLT Specification.
The last remaining element is the LINK tag. The easiest way to process that tag will be to set up a named template that we can drive with a parameter:
<xsl:template name="htmLink"> <xsl:param name="dest" select="UNDEFINED"/> <xsl:element name="a"> <xsl:attribute name="href"> <xsl:value-of select="$dest"/> </xsl:attribute> <xsl:apply-templates/> </xsl:element> </xsl:template>
The major difference in this template is that, instead of specifying a match clause, you gave the template a name with the name="" clause. So this template only gets executed when you invoke it.
Within the template, you also specified a parameter named dest, using the <xsl:param> tag. For a bit of error checking, you used the select clause to give that parameter a default value of UNDEFINED. To reference the variable in the <xsl:value-of> tag, you specified "$dest".
Recall that an entry in quotes is interpreted as an expression, unless it is further enclosed in single quotes. That's why the single quotes were needed earlier, in "@type='ordered'"--to make sure that ordered was interpreted as a string.
The <xsl:element> tag generates an element. Previously, we have been able to simply specify the element we want by coding something like <html>. But here you are dynamically generating the content of the HTML anchor (<a>) in the body of the <xsl:element> tag. And you are dynamically generating the href attribute of the anchor using the <xsl:attribute> tag.
The last important part of the template is the <apply-templates> tag, which inserts the text from the text node under the LINK element. Without it, there would be no text in the generated HTML link.
Next, add the template for the LINK tag, and call the named template from within it:
<xsl:template match="LINK"> <xsl:if test="@target"> <!--Target attribute specified.--> <xsl:call-template name="htmLink"> <xsl:with-param name="dest" select="@target"/> </xsl:call-template> </xsl:if> </xsl:template> <xsl:template name="htmLink"> ...
The test="@target" clause returns true if the target attribute exists in the LINK tag. So this <xsl-if> tag generates HTML links when the text of the link and the target defined for it are different.
The <xsl:call-template> tag invokes the named template, while <xsl:with-param> specifies a parameter using the name clause, and its value using the select clause.
As the very last step in the stylesheet construction process, add the <xsl-if> tag shown below to process LINK tags that do not have a target attribute.
<xsl:template match="LINK"> <xsl:if test="@target"> ... </xsl:if> <xsl:if test="not(@target)"> <xsl:call-template name="htmLink"> <xsl:with-param name="dest"> <xsl:apply-templates/> </xsl:with-param> </xsl:call-template> </xsl:if> </xsl:template>
The not(...) clause inverts the previous test (remember, there is no else clause). So this part of the template is interpreted when the target attribute is not specified. This time, the parameter value comes not from a select clause, but from the contents of the <xsl:with-param> element.
Just to make it explicit: Parameters and variables (which are discussed in a few moments in What Else Can XSLT Do? can have their value specified either by a select clause, which lets you use XPath expressions, or by the content of the element, which lets you use XSLT tags.
The content of the parameter, in this case, is generated by the <xsl:apply-templates/> tag, which inserts the contents of the text node under the LINK element.
Run the Program
When you run the program now, the results should look something like this:
...
<h2>The <I>Third</I> Major Section
</h2>
<p>In addition to the inline tag in the heading, this section
defines the term <i>inline</i>, which literally
means
"no line break". It also adds a simple link to the
main page for the Java platform (<a
href="http://java.sun.com">http://java.sun.com</a>),
as well as a link to the
<a href="http://java.sun.com/xml">XML</a> page.
</p>
Transforming from the Command Line
When you are running a transformation from the command line, it makes a lot of sense to use XSLTC. Although the Xalan interpreting transformer contains a command-line mechanism as well, it doesn't save the pre-compiled byte-codes as translets for later use, as XSLTC does.
There are two steps to running XSLTC from the command line:
- Compile the translet.
- Run the compiled translet on the data.
For detailed information on this subject, you can also consult the excellent usage guide at http://xml.apache.org/xalan-j/xsltc_usage.html.
Compiling the Translet
To compile the article3.xsl stylesheet into a translet, execute this command:
java org.apache.xalan.xsltc.cmdline.Compile article3.xsl
For version 1.3 of the Java platform, you'll need to include the appropriate classpath settings, as described in Compiling and Running the Program.
The result is a class file (the translet) named article3.class.
Here are the arguments that can be specified when compiling a translet:
java org.apache.xalan.xsltc.cmdline.Compile
-o transletName -d directory -j jarFile
-p packageName {-u stylesheetURI | stylesheetFile }
where:
- -o transletName
- Specifies the name of the generated translet class (the output class).The .class suffix is optional. If not present, it is automatically added to the name specified by the stylesheet argument.
- -d directory
- Specifies the destination directory. (Default is the current working directory.)
- -j jarFile
- -p packageName
- Specifies a package name for the generated translet classes.
- -u stylesheetURI
- Specifies the stylesheet with a URI such as http://myserver/stylesheet1.xsl.
- stylesheetFile
- (No flag) The pathname of the stylesheet file.
Running the Translet
To run the compiled translet on the sample file article3.xml, execute this command:
java org.apache.xalan.xsltc.cmdline.Transform
article3.xml article3
Again set the classpath, as described in Compiling and Running the Program, if you are running on version 1.3 of the Java platform.
This command adds the current directory to the classpath, so the translet can be found. The output goes to System.out.
Here are the possible arguments that can be specified when running a translet:
java org.apache.xalan.xsltc.cmdline.Transform
{-u documentURI | documentFilename}
className [name=value...]
where:
- -u documentURI
- Specifies the XML input document with a URI.
- documentFilename
- Specifies the filename for an XML input document.
- className
- The translet that performs the transformation. (Here, you can't specify the .class suffix, the same way you omit it when running a java application.)
- name=value ...
- Optional set of one or more stylesheet parameters specified as name-value pairs.
Concatenating Transformations with a Filter Chain
It is sometimes useful to create a filter chain -- a concatenation of XSLT transformations in which the output of one transformation becomes the input of the next. This section of the tutorial shows you how to do that.
Writing the Program
Start by writing a program to do the filtering. This example will show the full source code, but you can use one of the programs you've been working on as a basis, to make things easier.
The code described here is contained in FilterChain.java.
The sample program includes the import statements that identify the package locations for each class:
import javax.xml.parsers.FactoryConfigurationError; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; import org.xml.sax.InputSource; import org.xml.sax.XMLReader; import org.xml.sax.XMLFilter; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.sax.SAXTransformerFactory; import javax.xml.transform.sax.SAXSource; import javax.xml.transform.sax.SAXResult; import javax.xml.transform.stream.StreamSource; import javax.xml.transform.stream.StreamResult; import java.io.*;
The program also includes the standard error handlers you're used to. They're listed here, just so they are all gathered together in one place:
} catch TransformerConfigurationException(tce) { // Error generated by the parser System.out.println ("* Transformer Factory error"); System.out.println(" " + tce.getMessage() ); // Use the contained exception, if any Throwable x = tce; if (tce.getException() != null) x = tce.getException(); x.printStackTrace(); } catch TransformerException(te) { // Error generated by the parser System.out.println ("* Transformation error"); System.out.println(" " + te.getMessage() ); // Use the contained exception, if any Throwable x = te; if (te.getException() != null) x = te.getException(); x.printStackTrace(); } catch SAXException(sxe) { // Error generated by this application // (or a parser-initialization error) Exception x = sxe; if (sxe.getException() != null) x = sxe.getException(); x.printStackTrace(); } catch ParserConfigurationException(pce) { // Parser with specified options can't be built pce.printStackTrace(); } catch IOException(ioe) { // I/O error ioe.printStackTrace(); }
In between the import statements and the error handling, the core of the program consists of the code shown below.
public static void main String(argv[]) { if (argv.length != 3) { System.err.println ( "Usage: java FilterChain style1 style2 xmlfile"); System.exit (1); } try { // Read the arguments File stylesheet1 = new File(argv[0]); File stylesheet2 = new File(argv[1]); File datafile = new File(argv[2]); // Set up the input stream BufferedInputStream bis = new BufferedInputStream(newFileInputStream(datafile)); InputSource input = new InputSource(bis); // Set up to read the input file (see Note #1) SAXParserFactory spf = SAXParserFactory.newInstance(); spf.setNamespaceAware(true); SAXParser parser = spf.newSAXParser(); XMLReader reader = parser.getXMLReader(); // Create the filters (see Note #2) SAXTransformerFactory stf = (SAXTransformerFactory) TransformerFactory.newInstance(); XMLFilter filter1 = stf.newXMLFilter( new StreamSource(stylesheet1)); XMLFilter filter2 = stf.newXMLFilter( new StreamSource(stylesheet2)); // Wire the output of the reader to filter1 (see Note #3) // and the output of filter1 to filter2 filter1.setParent(reader); filter2.setParent(filter1); // Set up the output stream StreamResult result = new StreamResult(System.out); // Set up the transformer to process the SAX events generated // by the last filter in the chain Transformer transformer = stf.newTransformer(); SAXSource transformSource = new SAXSource( filter2, input); transformer.transform(transformSource, result); } catch (...) { ...
Notes:
- The Xalan transformation engine currently requires a namespace-aware SAX parser. XSLTC does not make that requirement.
- This weird bit of code is explained by the fact that SAXTransformerFactory extends TransformerFactory, adding methods to obtain filter objects. The newInstance() method is a static method defined in TransformerFactory, which (naturally enough) returns a TransformerFactory object. In reality, though, it returns a SAXTransformerFactory. So, to get at the extra methods defined by SAXTransformerFactory, the return value must be cast to the actual type.
- An XMLFilter object is both a SAX reader and a SAX content handler. As a SAX reader, it generates SAX events to whatever object has registered to receive them. As a content handler, it consumes SAX events generated by its "parent" object -- which is, of necessity, a SAX reader, as well. (Calling the event generator a "parent" must make sense when looking at the internal architecture. From an external perspective, the name doesn't appear to be particularly fitting.) The fact that filters both generate and consume SAX events allows them to be chained together.
Understanding How the Filter Chain Works
The code listed above shows you how to set up the transformation. Figure 2 should help you understand what's happening when it executes.
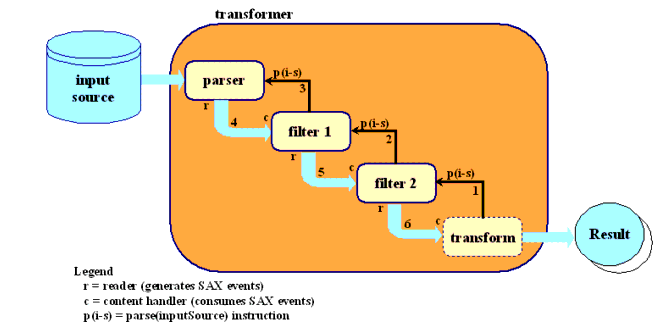
Figure 2 Operation of Chained Filters
When you create the transformer, you pass it at a SAXSource object, which encapsulates a reader (in this case, filter2) and an input stream. You also pass it a pointer to the result stream, where it directs its output. The diagram shows what happens when you invoke transform() on the transformer. Here is an explanation of the steps:
- The transformer sets up an internal object as the content handler for filter2, and tells it to parse the input source.
- filter2, in turn, sets itself up as the content handler for filter1, and tells it to parse the input source.
- filter1, in turn, tells the parser object to parse the input source.
- The parser does so, generating SAX events which it passes to filter1.
- filter1, acting in its capacity as a content handler, processes the events and does its transformations. Then, acting in its capacity as a SAX reader (XMLReader), it sends SAX events to filter2.
- filter2 does the same, sending its events to the transformer's content handler, which generates the output stream.
Testing the Program
To try out the program, you'll create an XML file based on a tiny fraction of the XML DocBook format, and convert it to the ARTICLE format defined here. Then you'll apply the ARTICLE stylesheet to generate an HTML version.
This example processes small-docbook-article.xml using docbookToArticle.xsl and article1c.xsl. The result is filterout.html (The browser-displayable versions are small-docbook-article.xml.html, docbookToArticle.xsl.html, article1c.xsl.html, and filterout-src.html.) See the O'Reilly Web pages for a good description of the DocBook article format.
Start by creating a small article that uses a minute subset of the XML DocBook format:
<?xml version="1.0"?>
<Article>
<ArtHeader>
<Title>Title of my (Docbook) article</Title>
</ArtHeader>
<Sect1>
<Title>Title of Section 1.</Title>
<Para>This is a paragraph.</Para>
</Sect1>
</Article>
Next, create a stylesheet to convert it into the ARTICLE format:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0" > <xsl:output method="xml"/> (see Note #1) <xsl:template match="/"> <ARTICLE> <xsl:apply-templates/> </ARTICLE> </xsl:template> <!-- Lower level titles strip element tag --> (see Note #2) <!-- Top-level title --> <xsl:template match="/Article/ArtHeader/Title"> (Note #3) <TITLE> <xsl:apply-templates/> </TITLE> </xsl:template> <xsl:template match="//Sect1"> (see Note #4) <SECT><xsl:apply-templates/></SECT> </xsl:template> <xsl:template match="Para"> <PARA><xsl:apply-templates/></PARA> (see Note #5) </xsl:template> </xsl:stylesheet>
Notes:
- This time, the stylesheet is generating XML output.
- The template that follows (for the top-level title element) matches only the main title. For section titles, the TITLE tag gets stripped. (Since no template conversion governs those title elements, they are ignored. The text nodes they contain, however, are still echoed as a result of XSLT's built in template rules-- so only the tag is ignored, not the text. More on that below.)
- The title from the DocBook article header becomes the ARTICLE title.
- Numbered section tags are converted to plain SECT tags.
- This template carries out a case conversion, so Para becomes PARA.
Although it hasn't been mentioned explicitly, XSLT defines a number of built-in (default) template rules. The complete set is listed in Section 5.8 of the specification. Mainly, they provide for the automatic copying of text and attribute nodes, and for skipping comments and processing instructions. They also dictate that inner elements are processed, even when their containing tags don't have templates. That is the reason that the text node in the section title is processed, even though the section title is not covered by any template.
Now, run the FilterChain program, passing it the stylesheet above (docbookToArticle.xsl), the ARTICLE stylesheet (article1c.xsl), and the small DocBook file (small-docbook-article.xml), in that order. The result should like this:
<html> <body> <h1 align="center">Title of my (Docbook) article</h1> <h2>Title of Section 1.</h2> <p>This is a paragraph.</p> </body> </html>
This output was generated using JAXP 1.0. However, the first filter in the chain is not currently translating any of the tags in the input file. Until that defect is fixed, the output you see will consist of concatenated plain text in the HTML output, like this: "Title of my (Docbook) article Title of Section 1. This is a paragraph.".
Further Information
For more information on XSL stylesheets, XSLT, and transformation engines, see:
- Michael Kay's XSLT Programmer's Reference.
- www.xfront.com/rescuing-xslt.html
- Extensible Stylesheet Language (XSL): http://www.w3.org/Style/XSL/
- The XML Path Language: http://www.w3.org/TR/xpath
- The Xalan transformation engine: http://xml.apache.org/xalan-j/
- The XSLTC transformation engine: http://xml.apache.org/xalan-j/
- Tips for using XSLTC: http://xml.apache.org/xalan-j/xsltc_usage.html
- Designing stylesheets to maximize performance with XSLTC: http://xml.apache.org/xalan-j/xsltc/xsltc_performance.html
Generating XML from an Arbitrary Data Structure
In this section, you'll use XSLT to convert an arbitrary data structure to XML.
In general outline, then:
- You'll modify an existing program that reads the data, in order to make it generate SAX events. (Whether that program is a real parser or simply a data filter of some kind is irrelevant for the moment.)
- You'll then use the SAX "parser" to construct a SAXSource for the transformation.
- You'll use the same StreamResult object you created in the last exercise, so you can see the results. (But note that you could just as easily create a DOMResult object to create a DOM in memory.)
- You'll wire the source to the result, using the transformer object to make the conversion.
For starters, you need a data set you want to convert and a program capable of reading the data. In the next two sections, you'll create a simple data file and a program that reads it.
Creating a Simple File
We'll start by creating a data set for an address book. You can duplicate the process, if you like, or simply make use of the data stored in PersonalAddressBook.ldif.
The file shown below was produced by creating a new address book in Netscape Messenger, giving it some dummy data (one address card) and then exporting it in LDIF format.
LDIF stands for LDAP Data Interchange Format. LDAP, turn, stands for Lightweight Directory Access Protocol. I prefer to think of LDIF as the "Line Delimited Interchange Format", since that is pretty much what it is.
Figure 1 shows the address book entry that was created.
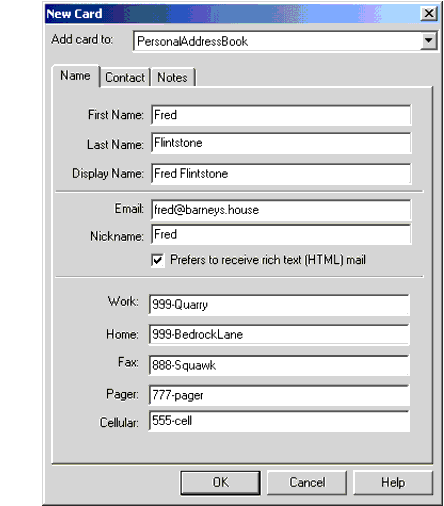
Figure 1 Address Book Entry
Exporting the address book produces a file like the one shown below. The parts of the file that we care about are shown in bold.
dn: cn=Fred Flintstone,mail=fred@barneys.house modifytimestamp: 20010409210816Z cn: Fred Flintstone xmozillanickname: Fred mail: Fred@barneys.house xmozillausehtmlmail: TRUE givenname: Fred sn: Flintstone telephonenumber: 999-Quarry homephone: 999-BedrockLane facsimiletelephonenumber: 888-Squawk pagerphone: 777-pager cellphone: 555-cell xmozillaanyphone: 999-Quarry objectclass: top objectclass: person
Note that each line of the file contains a variable name, a colon, and a space followed by a value for the variable. The sn variable contains the person's surname (last name) and the variable cn contains the DisplayName field from the address book entry.
Creating a Simple Parser
The next step is to create a program that parses the data.
The code discussed in this section is in AddressBookReader01.java. The output is in AddressBookReaderLog01.txt.
The text for the program is shown below. It's an absurdly simple program that doesn't even loop for multiple entries because, after all, it's just a demo!
import java.io.*; public class AddressBookReader { public static void main String(argv[]) { // Check the arguments if (argv.length != 1) { System.err.println ( "Usage: java AddressBookReader filename"); System.exit (1); } String filename = argv[0]; File f = new File(filename); AddressBookReader01 reader = new AddressBookReader01(); reader.parse(f); } /** Parse the input */ public void parse File(f) { try { // Get an efficient reader for the file FileReader r = new FileReader(f); BufferedReader br = new BufferedReader(r); // Read the file and display it's contents. String line = br.readLine(); while (null != (line = br.readLine())) { if (line.startsWith("xmozillanickname: ")) break; } output("nickname", "xmozillanickname", line); line = br.readLine(); output("email", "mail", line); line = br.readLine(); output("html", "xmozillausehtmlmail", line); line = br.readLine(); output("firstname","givenname", line); line = br.readLine(); output("lastname", "sn", line); line = br.readLine(); output("work", "telephonenumber", line); line = br.readLine(); output("home", "homephone", line); line = br.readLine(); output("fax", "facsimiletelephonenumber", line); line = br.readLine(); output("pager", "pagerphone", line); line = br.readLine(); output("cell", "cellphone", line); } catch Exception(e) { e.printStackTrace(); } } void output String(name, String prefix, String line) { int startIndex = prefix.length() + 2; // 2=length of ": " String text = line.substring(startIndex); System.out.println(name + ": " + text); } }
This program contains three methods:
- main
- The main method gets the name of the file from the command line, creates an instance of the parser, and sets it to work parsing the file. This method will be going away when we convert the program into a SAX parser. (That's one reason for putting the parsing code into a separate method.)
- parse
- This method operates on the File object sent to it by the main routine. As you can see, it's about as simple as it can get. The only nod to efficiency is the use of a BufferedReader, which can become important when you start operating on large files.
- output
- The output method contains the logic for the structure of a line. Starting from the right It takes three arguments. The first argument gives the method a name to display, so we can output "html" as a variable name, instead of "xmozillausehtmlmail". The second argument gives the variable name stored in the file (xmozillausehtmlmail). The third argument gives the line containing the data. The routine then strips off the variable name from the start of the line and outputs the desired name, plus the data.
Running this program on PersonalAddressBook.ldif produces this output:
nickname: Fred email: Fred@barneys.house html: TRUE firstname: Fred lastname: Flintstone work: 999-Quarry home: 999-BedrockLane fax: 888-Squawk pager: 777-pager cell: 555-cell
I think we can all agree that's a bit more readable.
Modifying the Parser to Generate SAX Events
The next step is to modify the parser to generate SAX events, so you can use it as the basis for a SAXSource object in an XSLT transform.
The code discussed in this section is in AddressBookReader02.java.
Start by importing the additional classes you're going to need:
import java.io.*; import org.xml.sax.*; import org.xml.sax.helpers.AttributesImpl;
Next, modify the application so that it extends XmlReader. That change converts the application into a parser that generates the appropriate SAX events.
public class AddressBookReader implements XMLReader {
Now, remove the main method. You won't be needing that any more.
public static void main String(argv[]) { // Check the arguments if (argv.length != 1) { System.err.println ("Usage: Java AddressBookReader filename"); System.exit (1); } String filename = argv[0]; File f = new File(filename); AddressBookReader02 reader = new AddressBookReader02(); reader.parse(f);}
Add some global variables that will come in handy in a few minutes:
public class AddressBookReader implements XMLReader { ContentHandler handler; // We're not doing namespaces, and we have no // attributes on our elements. String nsu = ""; // NamespaceURI Attributes atts = new AttributesImpl(); String rootElement = "addressbook"; String indent = "\n "; // for readability!
The SAX ContentHandler is the object that is going to get the SAX events the parser generates. To make the application into an XmlReader, you'll be defining a setContentHandler method. The handler variable will hold a reference to the object that is sent when setContentHandler is invoked.
And, when the parser generates SAX element events, it will need to supply namespace and attribute information. Since this is a simple application, you're defining null values for both of those.
You're also defining a root element for the data structure (addressbook), and setting up an indent string to improve the readability of the output.
Next, modify the parse method so that it takes an InputSource as an argument, rather than a File, and account for the exceptions it can generate:
public void parse(File f)InputSource input) throws IOException, SAXException
Now make the changes shown below to get the reader encapsulated by the InputSource object:
try {
// Get an efficient reader for the file
FileReader r = new FileReader(f);
java.io.Reader r = input.getCharacterStream();
BufferedReader Br = new BufferedReader(r);
In the next section, you'll create the input source object and what you put in it will, in fact, be a buffered reader. But the AddressBookReader could be used by someone else, somewhere down the line. This step makes sure that the processing will be efficient, regardless of the reader you are given.
The next step is to modify the parse method to generate SAX events for the start of the document and the root element. Add the code highlighted below to do that:
/** Parse the input */ public void parse InputSource(input) ... { try { ... // Read the file and display its contents. String line = br.readLine(); while (null != (line = br.readLine())) { if (line.startsWith("xmozillanickname: ")) break; } if (handler==null) { throw new SAXException("No content handler"); } handler.startDocument(); handler.startElement(nsu, rootElement, rootElement, atts); output("nickname", "xmozillanickname", line); ... output("cell", "cellphone", line); handler.ignorableWhitespace("\n".toCharArray(), 0, // start index 1 // length ); handler.endElement(nsu, rootElement, rootElement); handler.endDocument(); } catch Exception(e) { ...
Here, you first checked to make sure that the parser was properly configured with a ContentHandler. (For this app, we don't care about anything else.) You then generated the events for the start of the document and the root element, and finished by sending the end-event for the root element and the end-event for the document.
A couple of items are noteworthy, at this point:
- We haven't bothered to send the setDocumentLocator event, since that is optional. Were it important, that event would be sent immediately before the startDocument event.
- We've generated an ignorableWhitespace event before the end of the root element. This, too, is optional, but it drastically improves the readability of the output, as you'll see in a few moments. (In this case, the whitespace consists of a single newline, which is sent the same way that characters are sent to the characters method: as a character array, a starting index, and a length.)
Now that SAX events are being generated for the document and the root element, the next step is to modify the output method to generate the appropriate element events for each data item. Make the changes shown below to do that:
void output String(name, String prefix, String line) throws SAXException { int startIndex = prefix.length() + 2; // 2=length of ": " String text = line.substring(startIndex);System.out.println(name + ": " + text);int textLength = line.length() - startIndex; handler.ignorableWhitespace(indent.toCharArray(), 0, // start index indent.length() ); handler.startElement(nsu, name, name /*"qName"*/, atts); handler.characters(line.toCharArray(), startIndex, textLength); handler.endElement(nsu, name, name); }
Since the ContentHandler methods can send SAXExceptions back to the parser, the parser has to be prepared to deal with them. In this case, we don't expect any, so we'll simply allow the application to fail if any occur.
You then calculate the length of the data, and once again generate some ignorable whitespace for readability. In this case, there is only one level of data, so we can use a fixed-indent string. (If the data were more structured, we would have to calculate how much space to indent, depending on the nesting of the data.)
The indent string makes no difference to the data, but will make the output a lot easier to read. Once everything is working, try generating the result without that string! All of the elements will wind up concatenated end to end, like this:<addressbook><nickname>Fred</nickname><email>...
Next, add the method that configures the parser with the ContentHandler that is to receive the events it generates:
void output String(name, String prefix, String line) throws SAXException { ... } /** Allow an application to register a content event handler. */ public void setContentHandler(ContentHandler handler) { this.handler = handler; } /** Return the current content handler. */ public ContentHandler getContentHandler() { return this.handler; }
There are several more methods that must be implemented in order to satisfy the XmlReader interface. For the purpose of this exercise, we'll generate null methods for all of them. For a production application, though, you may want to consider implementing the error handler methods to produce a more robust app. For now, though, add the code highlighted below to generate null methods for them:
/** Allow an application to register an error event handler. */ public void setErrorHandler ErrorHandler(handler) { } /** Return the current error handler. */ public ErrorHandler getErrorHandler() { return null; }
Finally, add the code highlighted below to generate null methods for the remainder of the XmlReader interface. (Most of them are of value to a real SAX parser, but have little bearing on a data-conversion application like this one.)
/** Parse an XML document from a system identifier (URI). */ public void parse String(systemId) throws IOException, SAXException { } /** Return the current DTD handler. */ public DTDHandler getDTDHandler() { return null; } /** Return the current entity resolver. */ public EntityResolver getEntityResolver() { return null; } /** Allow an application to register an entity resolver. */ public void setEntityResolver EntityResolver(resolver) { } /** Allow an application to register a DTD event handler. */ public void setDTDHandler DTDHandler(handler) { } /** Look up the value of a property. */ public Object getProperty String(name) { return null; } /** Set the value of a property. */ public void setProperty String(name, Object value) { } /** Set the state of a feature. */ public void setFeature String(name, boolean value) { } /** Look up the value of a feature. */ public boolean getFeature String(name) { return false; }
Congratulations! You now have a parser you can use to generate SAX events. In the next section, you'll use it to construct a SAX source object that will let you transform the data into XML.
Using the Parser as a SAXSource
Given a SAX parser to use as an event source, you can (easily!) construct a transformer to produce a result. In this section, you'll modify the TransformerApp you've been working with to produce a stream output result, although you could just as easily produce a DOM result.
The code discussed in this section is in TransformationApp04.java. The results of running it are in TransformationLog04.txt.
Important!
Make sure you put the AddressBookReader aside and open up the TransformationApp. The work you do in this section affects the TransformationApp! (The look pretty similar, so it's easy to start working on the wrong one.)
Start by making the changes shown below to import the classes you'll need to construct a SAXSource object. (You won't be needing the DOM classes at this point, so they are discarded here, although leaving them in doesn't do any harm.)
import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; import org.xml.sax.ContentHandler; import org.xml.sax.InputSource;import org.w3c.dom.Document; import org.w3c.dom.DOMException;...import javax.xml.transform.dom.DOMSource;import javax.xml.transform.sax.SAXSource; import javax.xml.transform.stream.StreamResult;
Next, remove a few other holdovers from our DOM-processing days, and add the code to create an instance of the AddressBookReader:
public class TransformationApp {// Global value so it can be ref'd by the tree-adapter static Document document;public static void main String(argv[]) { ...DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//factory.setNamespaceAware(true); //factory.setValidating(true);// Create the sax "parser". AddressBookReader saxReader = new AddressBookReader(); try { File f = new File(argv[0]);DocumentBuilder builder = factory.newDocumentBuilder(); document = builder.parse(f);
Guess what! You're almost done. Just a couple of steps to go. Add the code highlighted below to construct a SAXSource object:
// Use a Transformer for output ... Transformer transformer = tFactory.newTransformer(); // Use the parser as a SAX source for input FileReader fr = new FileReader(f); BufferedReader br = new BufferedReader(fr); InputSource inputSource = new InputSource(br); SAXSource source = new SAXSource(saxReader, inputSource); StreamResult result = new StreamResult(System.out); transformer.transform(source, result);
Here, you constructed a buffered reader (as mentioned earlier) and encapsulated it in an input source object. You then created a SAXSource object, passing it the reader and the InputSource object, and passed that to the transformer.
When the application runs, the transformer will configure itself as the ContentHandler for the SAX parser (the AddressBookReader) and tell the parser to operate on the inputSource object. Events generated by the parser will then go to the transformer, which will do the appropriate thing and pass the data on to the result object.
Finally, remove the exceptions you no longer need to worry about, since the TransformationApp no longer generates them:
catch SAXParseException(spe) { // Error generated by the parser System.out.println("\n** Parsing error" + ", line " + spe.getLineNumber() + ", uri " + spe.getSystemId()); System.out.println(" " + spe.getMessage() ); // Use the contained exception, if any Exception x = spe; if (spe.getException() != null) x = spe.getException(); x.printStackTrace(); } catch SAXException(sxe) { // Error generated by this application // (or a parser-initialization error) Exception x = sxe; if (sxe.getException() != null) x = sxe.getException(); x.printStackTrace(); } catch ParserConfigurationException(pce) { // Parser with specified options can't be built pce.printStackTrace();} catch IOException(ioe) { ...
You're done! You have now created a transformer which will use a SAXSource as input, and produce a StreamResult as output.
Doing the Conversion
Now run the application on the address book file. Your output should look like this:
<?xml version="1.0" encoding="UTF-8"?> <addressbook> <nickname>Fred</nickname> <email>fred@barneys.house</email> <html>TRUE</html> <firstname>Fred</firstname> <lastname>Flintstone</lastname> <work>999-Quarry</work> <home>999-BedrockLane</home> <fax>888-Squawk</fax> <pager>777-pager</pager> <cell>555-cell</cell> </addressbook>
