WebSphere Extreme Scale with WebSphere Commerce v7
|
Overview
|
Architecture |
Topologies |
Overview
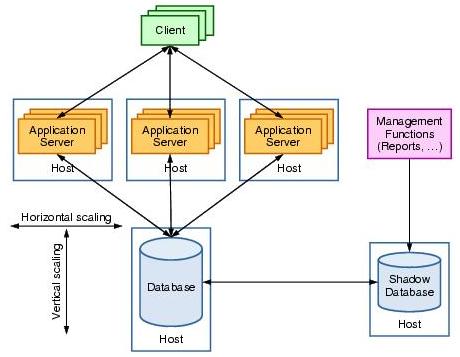
Scalability is the ability of a system to handle increasing load in a graceful manner.Two scaling options...
| Horizontal | Add additional hosts to a tier (scale out) |
| Vertical | Add CPUs, memory, etc.. to a single system (scale up) |
With linear scaling, doubling CPU capacity doubles maximum throughput.
Saturation is reached when throughput cannot be increased due to a bottleneck resource.

Because application servers can be effectively scaled horizontally to provide additional memory and processing cycles to service requests, the database is usually the bottleneck resource. The progressive approach to fix is to...
- Scale out by adding additional database servers
- Use a high speed connections between DB servers in a cluster
This approach is viable, but poses challenges in keeping database servers synchronized for data integrity and crash recovery. For example, consider two concurrent transactions that modify the same row in the database. When these transactions are executed by separate database servers, communication is required to ensure the atomic, consistent, isolated, and durable (ACID) attributes of database transaction are preserved. This communication can grow exponentially as the number of database servers increases, which ultimately limits the scalability of the database. In fact, although application server clusters with more than 100 hosts can be easily found, a database server cluster with more then four members is hard to find.
The scalability challenge is to provide scalable access to large amounts of data. In almost all application scenarios, scalability is treated as a competitive advantage. It directly impacts the business applications and the business unit that owns the applications. Applications that are scalable can easily accommodate growth and aid the business functions in analysis and business development. You want to be able to scale your product with predictable costs without requiring a redeployment of an application or topology.
A typical approach to resolving performance and therefore scalability problems is to implement caching of the data. The cache is a copy of frequently accessed data that is held in memory to reduce the access time to the data. This has the effect of placing the data closer to the application, which improves performance and throughput. It also reduces the number of requests to the database, reducing that resource's likelihood of being a bottleneck.
A cache simply extends the storage capability. It can be considered to act as a shock absorber to the database. The cache sits between the application and the database to reduce the load on the database.

Although a cache can reduce the load on the database, the same data might be cached in several servers simultaneously. Things become complicated when one copy of the data is changed, because all cached copies need to be either invalidated or updated.
For very large caching solutions, data grids are often used. In general terms, a grid is several loosely-coupled and heterogeneous computers that act together to perform large tasks. To accomplish this, a grid needs to be highly scalable. There are several forms of grids, depending on the task at hand.
The data grid can be located in the same JVM as the applications. This arrangement provides the fastest access to the data. However, as the data grid grows, it might not scale effectively because the application and grid share the same address space.
Another approach is to perform local caching in the application server tier (near cache) and to have the data grid cache implementation on a separate elastic tier where the servers are primarily only responsible for hosting the grid data. This architecture provides additional flexibility in designing the application topology and in the manner of client access (direct to the grid, or through the application server layer), and for the scalability and availability of the grid data...

As the use of the data grid technology increases, it is possible that the cache or data grid becomes the primary data access point. In this case, the database is used by the grid as a long term persistent data store. If the database is unavailable, the applications are still able to complete transactions against the grid so there is no loss of service to the application. The grid can push those updates to the database when it again becomes available. The database might also be required in application scenarios where logging or auditing of transactions is required for compliance or by regulations. In specialized use cases, such as transitory session state data, there might be no need to store the data from the grid into a database. Because the grid contains all of the information, data intensive computing tasks can then be moved into the grid and executed in parallel.
Both the IBM WebSphere DataPower XC10 Appliance and WXS software address scalability issues by introducing elastic data grids into your solution. The data grids hold cached data in a non-SQL structure, reducing read and write operations to the database.
This book focuses on solutions available today for integration of WXS. WebSphere eXtreme Scale caches data used by an application. It can be used to build a highly scalable, fault tolerant data grid with nearly unlimited horizontal scaling capabilities.
WXS creates infrastructure with the ability to deal with extreme levels of data processing and performance. When the data and resulting transactions experience incremental or exponential growth, the business performance does not suffer because the grid is easily extended by adding additional capacity in the form of JVMs and hardware.
Key features...
Grid containers
WXS server instances host data in grid containers.
WXS grid containers scale out to thousands of server instances by splitting and distributing data.
Communication between grid containers is limiting factor for scalability. Communication between grid containers is kept to a minimum, occurring only for...
- availability management
- data replication purposes
Grid data is kept highly available by having multiple instances of the data stored on separate servers and locations. This capability is defined when the grid is created.

Transaction support
WXS has transaction support for changes made to the cached data. Changes are committed or rolled back in an atomic way. Multiple individual operations that work in tandem are treated as a single unit of work. If even one individual operation fails, the entire transaction fails.
WXS acts as an intermediary between the application and database. It can also be the system of record for applications when no database or other data store is used.
As with other persistent store mechanisms, WXS uses transactions for the following reasons:
- To apply multiple changes as an atomic unit at commit time
- To ensure consistency of all cached data
- To isolate a thread from concurrent changes
- To act as the unit of replication to make the changes durable.
- To implement a life cycle for locks on changes
- To combine multiple changes to reduce the number of remote invocations
Security
Fine-grained control over client access to data can be enforced. WXS applications can enable security features and integrate with external security providers.
WXS includes the following security features:
Authentication Authenticate the identity of the client of the grid. This is done with credential information between the client and the grid server. Authorization Grant access only to authenticated clients. The authorization includes operations such as reading, querying, and modifying the data in the grid. Transport security Ensure secure communications between the remote clients and grid servers, and between the servers.
Runtime JVM support
WXS does not require WAS as a runtime application.
WXS can use any native JSE 1.4+ or JEE application server environment.
Annotations and JPA support are available with JSE 1.5 or later.
It is possible to access data stored in the grid from an ADO.NET Data Services client using REST API Data Services Framework. REST is available with WXS 7.0.0.0 cumulative fix 2 or later.
Monitoring techniques
The xsadmin utility can be used to view grid statistics. This utility is included with the standard installation.
The WXS web console provides a GUI view of grid statistics. The web console is included with the stand-alone installation of WXS.
JConsole can be leveraged to view the grid statistics. JConsole is not supported with WAS.
Custom MBean Scripts can be written to monitor the cache.
The Tivoli Performance Viewer shows grid statistics when you enable the Object Grid Related PMI statistics.
Third party monitoring products such as...
- CA Wily Introscope
- Hyperic HQ
IBM Tivoli Monitoring agent and Hyperic HQ gather data from WXS server side MBeans. CA Wily Introscope uses byte code instrumentation to display data.
When to use WXS
WXS provides a data grid to store data. How you access that grid, and the type of data you store in it can vary depending on the application. A detailed systems and design analysis is required to determine if, when, and how you use WXS. This is an important exercise for devising a road map for adoption of any new technology.
HTTP sessions
Many web applications use the HTTP session state management features provided by JEE application servers. Session state management allows the application to maintain state for the period of a user's interaction with the application. An example of this is a shopping cart, where information about intended purchases is stored until the shopping session is completed.
To support high-availability and failover, the state information must be available to all application server JVMs. Application servers typically achieve this by storing the state information in a shared database, or by performing memory-to-memory replication between JVMs.
- When HTTP session state is stored in a shared database, scalability is limited by the database server.
The disk I/O operations have a significant impact on application performance. When the transaction rate exceeds the capacity of the database server, the database server must be scaled up.
- When HTTP session state is replicated in memory between application servers, the limits to scalability vary depending on the replication scheme.
Commonly, a simple scheme is used in which each JVM holds a copy of all user session data, so the total amount of state information cannot exceed the available memory of any single JVM. Memory-to-memory replication schemes often trade consistency for performance, meaning that in cases of application server failure or user sessions being routed to multiple application servers, the user experience might be inconsistent and confusing.
WXS replaces the existing HTTP session state management facilities of the application server, placing the session data in a data grid.
WXS fetches user session information from the grid and writes changes back to the grid as necessary. Because the HTTP session data is transient in nature, it does not need to be backed up to disk and can be contained completely in a highly-available replicated grid. The grid is not constrained to any one application server product or to any particular management unit, such as WAS cells. User sessions can be shared between any set of application servers - even across data centers in the case of a failover scenario. This allows for a more reliable and fault-tolerant user session state.
There are two topologies you can use with HTTP session offloading:
- Co-located HTTP sessions
HTTP session grids coexist with the application in the JVMs. However, the session data is partitioned and distributed, making it highly scalable, fault tolerant, and faster.
- HTTP session offloading
HTTP session data grids are offloaded from the JVM running the application and placed into external WXS containers. This reduction of session data held in the application JVM can increase the efficiency of the application.
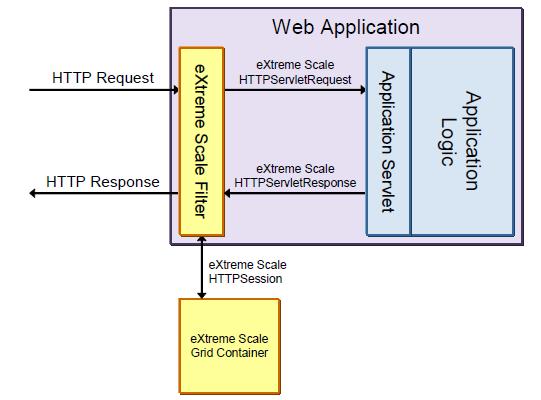
Dynamic cache
Dynamic page generation techniques, like JavaServer Pages (JSPs), often contain data that rarely changes, such as product details or information about corporate policies. Application servers generally provide an in-memory cache to store the generated output the first time the page is rendered to save the processing work and back-end system load for subsequent requests.
WAS's dynamic cache service stores the output of servlets, JSPs, and custom application objects. The dynamic cache service can be configured to off-load cached objects to disk, or to replicate cached objects across a cluster of application servers.
When the disk off-load option is enabled, the dynamic cache service extends its in-memory cache by writing cached objects to disk when the in-memory cache is full. If the working set of the application does not fit within the in-memory cache, disk access time becomes an important factor in application performance. Faster disk technologies, such as Storage Area Networks (SANs), are often used to improve performance.
When memory-to-memory cache replication is used, the size of the cache is limited to the available memory of any single JVM hosting the application. If the working set of the application outgrows the cache, the application will perform redundant work to re-create objects that have been evicted from the cache.
WXS provides a drop-in replacement for the dynamic cache service that stores cached objects in a grid, allowing the size of the cache to expand to the sum of all available memory in JVMs in the grid. The application's dynamic cache service policy remains in effect, so the carefully defined dependency and invalidation rules continue to function.
One benefit is that a newly started application server no longer has to warm up its cache before reaching peak performance. The cached data is already available to the application server from the grid. As a result, the application's performance is more reliable, and scaling out the application does not result in load spikes at the back-end systems.
Memory usage for caching can be reduced by as much as 70 percent compared to per-server disk off-load caches, owing to the reduced redundancy of a single shared cache. Additionally, the WXS dynamic cache service provider can compress the contents of the cache to save even more memory.
An example of using WXS as a dynamic cache provider can be seen in Chapter 6, Integrating WebSphere Commerce with WXS.
Application data cache
WXS can be used to cache internal application data that is not directly represented in a database or other back-end system.This expands the amount of such data that can be cached by the application and improves the cache hit rate by sharing the cache across application servers and, potentially, between related applications.
This type of caching must be implemented within the application, requiring development effort. For more information about using WXS as an application data cache, see User's Guide to WXS, SG24-7683.
Database cache
The back-end database is the scalability bottleneck for many database-centric applications. As the data volume and transaction rate expand, the application will eventually reach a point where the database server cannot be scaled up any further.
WXS can be used as a scalable, shared, coherent cache for databases and other data sources, reducing the load on the back-end systems and improving the performance of the application. It offers drop-in caching solutions for the OpenJPA and Hibernate database persistence layers, meaning that only configuration changes are required for certain applications.
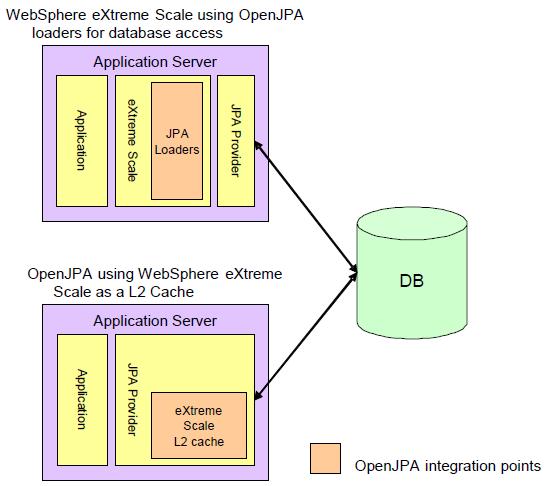
Using the grid as a data access layer
Using WXS as a data access layer allows access to its querying and indexing capabilities, which can reduce the load on back-end systems. This approach involves replacing the application's existing data access layer using the WXS programming interfaces. In this case, a grid acts as a cache for the database. The database remains the system of record, but all data access from the application goes through the cache grid. The application uses the WXS programming interfaces to access the data.
Using this method, the application can use the JPA-based database loader provided with WXS or a custom loader to retrieve and update grid entries from the back-end data store. For more information about using WXS as a data access layer, see User's Guide to WXS, SG24-7683. Another article of interest is IBM Extreme Transaction Processing (XTP) Patterns: Leveraging WXS as an in-line database buffer
Moving application processing into the grid
Beyond caching and data access scenarios, WXS offers a programming model for processing data sets in parallel within the grid containers that hold the data. Inserting a fully populated, partitioned, in-memory cache into the application architecture allows you to process the entire data set in parallel at local memory access speeds. Instead of fetching data from the back-end data store and processing it in series, the application can process the data in parallel across multiple grid containers and combine the results together.
This approach requires significant application design effort to identify the operations to perform within the grid, and to implement those operations using the WXS programming interfaces.
This approach enables parallel processing of large volumes of data in ways that were not practical without the grid. It might even be possible to run processes online that previously could only be run as batch jobs.
WebSphere Business Events uses WXS to handle complex event processing. An overview of this scenario can be found in Chapter 2, Integrating WXS with other middleware.
WebSphere Commerce and WXS
The WebSphere Commerce Server uses the WAS dynamic cache service to cache web and catalog content. The figure below shows a typical deployment of the default dynamic cache provider. Each Commerce application server contains the same cached data, which is replicated between the application servers on a best-effort basis to provide consistency of application performance.

The default dynamic cache architecture of the WebSphere Commerce Server poses the following challenges:
- Scalability
The dynamic cache capacity is determined by the individual JVM size. The scalability of the cache depends solely on how big an individual JVM can grow.
- Performance bottleneck due to disk off-loading
When the dynamic cache grows, it is practically impossible for a single JVM to hold all of the data, making it necessary to offload data to disk. Disk offloading decreases performance, and SAN or external storage is often required to offload the cache from the memory.
- Commerce performance
Commerce JVMs have large workloads to handle, in addition to holding cached data. A slight increase in the cache data exponentially affects the performance of the underlying JVM.
- Cache duplication and high invalidation traffic
The dynamic cache is a local cache, so to maintain consistency, the cache data is duplicated across all the cluster JVMs. This means that a change in dynamic cache content on one JVM creates invalidation traffic between the cluster JVMs.
- Constraints on core group scalability
Dynamic cache replication is done with the help of the data replication service (DRS) that runs in the underlying application server. The more members there are in a core group, the greater the performance loss, due to the increase of DRS traffic between the cluster JVMs. Management of huge core groups becomes a challenge in itself. Additional management tasks are required to split the larger core groups into smaller ones using bridging to provide consistent data.
- Cold cache
With the dynamic cache, every restart of the JVM requires the data to be populated from the backend systems. This can consume a large amount of time. In the case of a lazy cache loading scenario, where only a subset of the cache is initially loaded, the optimal performance of using dynamic cache is only achieved after a significant amount of time.
WXS benefits
The primary benefit in using WXS is to reduce the total cost of ownership of running a WebSphere Commerce deployment.Typical deployment...

By using WXS, you can make efficiency savings in a number of areas. The technical and business benefits include:
- Consistent and predictable performance as the site grows
The default dynamic cache provider in WAS is not designed to scale as effectively as WXS. It is designed to copy data to other application servers, which naturally has its limits. WXS is an elastic, self-healing grid technology that has proven linear scalability of throughput and data quantity while retaining consistent high performance.
- A disk or SAN is not required
Eliminating this requirement provides cost, performance, and scalability benefits. A cache in WXS can be very large, and an in-memory cache will be faster than a disk cache.
Consider how much disk space is needed. For example, the disk offload might be 20 Gb. This is duplicated n times for n servers. In our small example, this is 100 Gb of SAN requirement that is not needed for WXS.
- WebSphere Commerce is more efficient
With WXS, a Commerce application server can delegate all caching to another tier, and does not have to dedicate, for example, 30% of its memory to caching and a corresponding amount of CPU to manage cache replication, garbage collection and so on. Higher cache hit ratio and no duplication of cached data.
WXS stores the cached data in a single location, so all Commerce servers have access to the cache. Also, having no duplicated data removes the potential inconsistency of cached data where clients might receive different versions of cached pages from different servers. Having no duplication removes the communication needed to maintain cache consistency, making the cache more efficient in memory and CPU. And with no duplication of data there is less data to store. Compare this to dynamic cache. For example, each dynamic cache instance holds 400 Mb in memory, which is duplicated n times for n servers. For a small example of five Commerce servers, this is 1.6 Gb of wasted memory.
- Consistency and predictability of site performance
One area where WXS makes a big difference is when the Commerce servers need to be restarted. As part of the restart, the cache needs repopulating either by lazily recreating the cache, or by copying the data from another Commerce server. With either option there is a significant period after an application server restart where the site performance is well below optimal. WXS dramatically reduces site instability and warm-up time.
WXS architecture
Client view
Clients connect to a grid, and then access the maps in map sets.
Data is stored as key value pairs in the maps.

The key abstraction introduced by a map set is that it can be split into parts (partitioned) that can be spread over multiple containers.

WXS components
| Map | Interface that stores data as key-value pairs (duplicate keys are not supported).
Considered an associative data structure because it associates an object with a key. The key is the primary means of access to the data in the grid. The value part of the map is the data typically stored as a Java object. |
| Key | Java object instance that identifies a single cache value.
Keys can never change and must implement the equals() and hashCode() methods. |
| Value | Java object instance that contains the cache data.
The value is identified by the key and can be of any type. |
| Map set | Collection of maps whose entries are logically related.
More formally, a map set is a collection of maps that share a common partitioning scheme and replica strategy. |
| Grid | A collection of map sets. |
| Partitions | The concept of splitting data into smaller sections.
Partitioning allows the grid to store more data than can be accommodated in a single JVM. It is the fundamental concept that allows linear scaling. Partitioning happens at the map set level. The number of partitions is specified when the map set is defined. Data in the maps is striped across the N partitions using the key hashcode modulo N. Choosing the number of partitions for your data is an important consideration when configuring and designing for a scalable infrastructure. |
| Shards | Data in a partition is physically stored in shards.
A partition always has a primary shard. If replicas are defined for a map set, each partition will also have that number of replica shards. Replicas provide availability for the data in the grid. |
| Grid containers | Grid containers host shards, and thus provide the physical storage for the grid data. |
| Grid container server | A grid container server hosts grid containers.
WXS code can run in either in an application server or a stand-alone JSE JVM. Grid container servers are sometimes referred to as JVMs. |
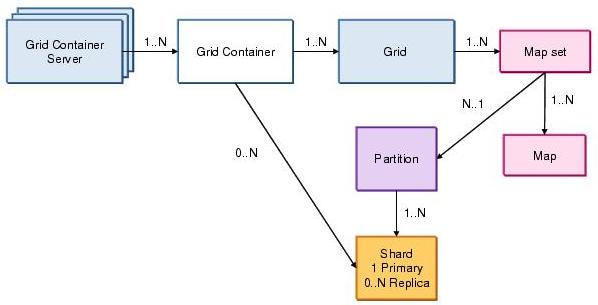
Grid container servers can host many grid containers and grids can be spread across many grid containers.
The catalog service places shards in grid containers.
A grid consists of a number of map sets, which are partitioned using a key. Each map in the map set is defined by a BackingMap. A map set is a collection of maps that are typically used together. Many map sets can exist in one grid.
A map holds grid data as key value pairs. A map set consists of a number of partitions. Each partition has a primary shard and N replica shards.
For example Grid A contains two map sets:
- The Red map set has three partitions (0, 1, and 2) and two replicas, for a total of nine shards. (three partitions times three shards for each partition, the primary plus two replicas).
- The Yellow map set has four partitions (0, 1, 2, and 3) and one replica, for a total of eight shards. This is one way the shards can be distributed over the available grid containers.

Grid client and servers
Grid server Catalog servers and grid containers (JVMs) The terms "grid server" and "ObjectGrid server" are interchangeable.
Grid client Clients connect to a grid and are attached to the whole grid. Any entity attached to the grid with any kind of request becomes a client.
Clients contain...
- ObjectMaps
- Near-cache copy of a BackingMap
The terms "grid client" and "ObjectGrid client" are interchangeable.
A grid client can maintain an independent copy (near-cache) of a subset of the server data (far-cache). The far-cache is always shared between clients. The near-cache (if in use) is shared between all threads of the grid client.
Clients can read data from multiple partitions in a single transaction. However, clients can only update a single partition in a transaction.
In our integration scenarios, we install the WXS Client on WebSphere Commerce Server for communicating with a remote grid.
Catalog service
The catalog service maintains the healthy operation of grid servers and containers. The catalog service is made highly available by starting more than one catalog service process.
The catalog service becomes the central nervous system of the grid operation by providing...
- Location service to all grid clients
- Health management of grid container servers
- Shard distribution and re-distribution
- Policy and rule enforcement

Shard placement
The catalog service evenly distributes primary and replica shards among registered container servers. As grid container servers leave and join the grid, shards are re-distributed.
The water flow algorithm...
- Ensures the equitable distribution of the total number of shards across the total number of available containers.
- Ensures that no one container is overloaded when other containers are available to host shards.
- Enables fault tolerance when the primary shard disappears (due to container failure or crash) by promoting a replica shard to primary shard.
If a replica shard disappears, another is created and placed on an appropriate container, preserving the placement rules. Other key aspects of the approach are that it minimizes the number of shards moved and the time required to calculate the shard distribution changes. Both of these concerns are important to allowing linear scaling.
For high availability WXS ensures that primary and replica shards of a partitions are never placed in the same container or even on the same machine.
Here are four partitions, each with a primary shard and one replica shard, distributed across four containers...
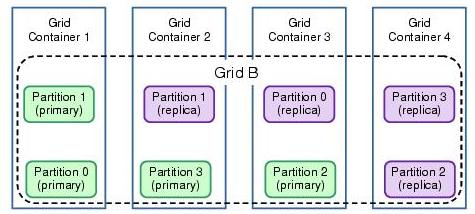
The figure below shows how the shard placement adjusts when one of the containers fails and only three containers are available for placement. In this case, no primary partitions were affected so no replicas were promoted to be primary partitions. The two failed replica partitions are simply recreated in another container in the grid.

Zone support
Zone support allows for rules-based shard placement.
Zone support provides better scalability as only the metadata shared by the catalog servers is synchronously replicated. Data objects are copied asynchronously across networks, imposing fewer burdens on enterprise networks by eliminating the requirement of real time replication.
As long as the catalog service sees zones being registered (as the zoned grid container servers come alive), the primary and replica shards are striped across zones.
The zone rules described in the grid deployment descriptor file dictate placement of synchronous or asynchronous replica shards in respective zones.
For optimal replication performance place synchronous replicas and asynchronous replicas in different zones. This placement is also optimal for...
- Scaling across geographies or data centers
- Ensuring high availability for grid container server failure in a local zone (synchronous replica)
- Ensuring high availability in a complete data center failure (asynchronous replica).
Typically, catalog servers are placed in each data center or zone, and the catalog servers synchronize their object/shard routing information. The catalog service must be clustered for high availability in every zone. The catalog service retains topology information of all of the containers and controls shard placement and routing for all clients.
Data is available to applications regardless of zoned location. The catalog service provides up-to-date routing information about the location of an object if the object is not found in the zone with the closest proximity to the application container.

Zone-based routing
WXS supports a routing preference for zones, local host, and local process that applies to hash-based fixed and per-container partitions
Proximity-based routing provides the capacity to minimize client traffic across zone boundaries to minimize client traffic across machines, and to minimize client traffic across processes.
Heap size and the number of JVMs
Although the WXS grid offers linear scalability, grid deployment, data size, and application patterns determine the size and volume of JVMs that make up the grid. This is also an important data point to facilitate future growth of the grid. Consider grid deployment factors such as estimated partition size, number of partitions, number of synchronous and asynchronous replicas, desired availability, zoned deployment over geographies, and so forth, when deciding the total JVMs and size (in terms of memory allocation) of JVMs that make up the grid.
Number of grids
A single grid infrastructure can support many logical grid instances, each containing a distinct set of maps and data. A single application can connect to multiple grid instances if required. In general, assign each application its own dedicated grid instance, except in cases where data is shared between applications.
Put a different way, multiple applications and multiple grids can share the same catalog service. In general, provide each logical set of grids used by one or more applications its own dedicated catalog service to maintain a separation of applications so that one application's problems do not cause failures in the other applications.
Catalog servers
Plan for catalog service high availability and sizing requirements. The decision on the number of catalog servers in the catalog service depends on overall grid size, desired high availability, and zones configuration. As a general rule, use at least two catalog servers for high availability, and at least one per zone.
Sizing for growth
WXS can scale linearly with growth. Growth imperatives include decisions and considerations regarding grid topology, hardware requirements and availability, and managed or stand-alone grid environment. The driving factors are the resource (hardware and software) availability and the set of tasks involved in adding grid containers to expand the grid on demand. This imperative can also include the decision points and operational procedures required to add to the grid capacity.Set the number of partitions high enough to allow for future growth. After the application is deployed, the number of partitions cannot be changed without restarting the entire grid. This means that beyond the point where there is one only one shard on each grid container JVM, adding more JVMs will not provide any benefit. A good general rule is 10 shards per grid container JVM.
Offloading data from server JVMs
Offloading data to an external JVM is the preferred topology when you face memory constraints or huge memory requirements with the existing environment. As we mentioned previously, WXS provides a highly scalable and elastic environment for large memory requirements and helps the application JVM work efficiently. In integration scenarios, you can offload dynamic caches and sessions from application JVMs to remote WXS JVMs.
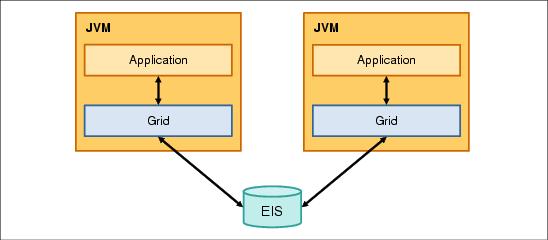
Remote managed WXS topology
The illustration below shows the grid installed in a WAS JVM and remote to the application (remote managed toplogy).

Remote managed topology gives you the following advantages:
- Offloading of session or cache data from the application JVMs helps the application respond faster
- Better management facilities using the Network Deployment administrative console
- Clustering and high availability management is taken care of by WebSphere Network Deployment
- Adding and removing grid members is easier
- Zones can be easily set up using the nodegroup facility
- Existing monitoring tools of the WebSphere Network Deployment environment can be easily leveraged
A disadvantage when using remote managed topology is the cost factor.
The remote managed topology is used in the examples below.
Remote stand-alone WXS topology
In this example the grid client communicates to the remote stand-alone grid server. The WAS container does not host the grid.
This setup provides all of the facilities provided by the embedded version except for WAS monitoring features.

Advantages when using remote stand-alone topology include:
- Cost savings because there are no WAS license issues involved.
- Session and dynamic cache offloading.
Disadvantages when using remote stand-alone topology include:
- Less administrative control due to the absence of WAS administrative console.
- Tivoli Performance Viewer and Cache Monitor only run in a WAS environment.
Embedded topology
In the local cache topology the application logic runs in the same JVM as the data in the grid. Each application can only access the local grid instance to store or retrieve data from its cache. In this case, WXS is used as a simple local cache.
This topology can perform faster than using a database if the needed data can be found in the local ObjectGrid. This avoids a remote procedure call (RPC) to the back-end data store. Using WXS as a local cache can also reduce the load on your back-end data store. This topology is not recommended for fault tolerance or high availability.
A big drawback with this approach is you have more than one cache for the data. In this case, you have to keep the caches in sync. If an object is cached in both JVMs and is changed in one of them, the other cache becomes outdated. The two caches must be set up to shared cache to resolve the object, which is difficult to set up. This topology also scales poorly as you add applications with local caches. Use the following topologies instead to use a shared cache and avoid the problem altogether. This topology works well only when the applications are reading the data and not making any changes.
Embedded partitioned topology
In the colocated application and cache topology, the application logic runs in the same JVM as the data in the grid. However, the data stored in the grid is spread across all of the JVMs that have WXS installed and configured.
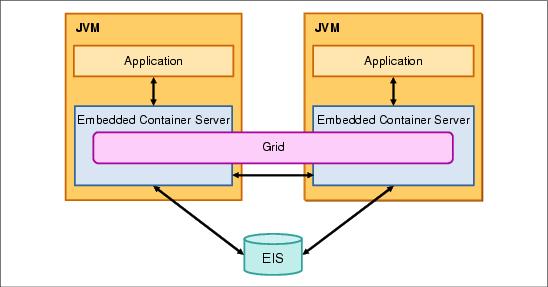
This topology can be faster than using a database because an application can take advantage of the grid near-cache to compensate for the RPC calls made when the requested data is stored on another server in the grid or can only be found in the back-end datastore. This topology can also reduce the load on your back-end datastore.
With this topology, replica shards that sit in a JVM other than the primary can be used to ensure fault tolerance and high availability.
High availability and multiple data center topologies
A zone-based topology helps enterprise computing environments distribute data cache across geographies for high availability and disaster recovery.
For distributed applications spanning multiple data centers, a multi-master topology helps in reducing data access time.
In this section, we compare two topologies:
Zone-based topology
Zone support provides control of shard placement in the WXS-enabled grid. By definition, zones can be considered as a set of grid containers that belong to a domain or exist within a boundary. Multiple zones can be envisioned to exist across WANs and LANs, or even in the same LAN, but one zone is not intended to span across a WAN. Instead, define multiple zones across a WAN and combine them to form one single grid. Such a topology includes the following advantages:
- High availability of data cache across geographies
- Proximity of data to the application
- Controlled rule-based replication
- Primary and replica can be placed in separate zones, satisfying the disaster recovery requirements
The replication of data in real time, such as HTTP session data and application data, was a concern in the past due to cost of network and computing resources. The effort and costs involved in achieving this type of replication outweighed the potential benefits. Slower network connections mean lower bandwidth and higher latency connections. Zone-based replication factors include the possibility of network partitions, latencies, network congestion, and other factors.
A WXS grid adjusts to this unpredictable environment in the following ways:
- Limiting heartbeat to reduce traffic and processing
- Exploiting the catalog service as a centralized location service

The catalog service uses the WAS high availability manager to group processes together for availability monitoring. Each grouping of the processes is a core group.
The core group manager dynamically groups the processes together. These processes are kept small to allow for scalability. Each core group elects a leader that has the added responsibility of sending status to the core group manager when individual members fail. The same status mechanism is used to discover when all the members of a group fail, which causes the communication with the leader to fail.
Multi-master topology
Using the multi-master asynchronous replication feature, two or more data grids can become exact mirrors of one another. This mirroring is accomplished using asynchronous replication among links connecting the grids together. Each grid is hosted in an independent catalog service domain, with its own catalog service, container servers, and a unique name.
With the multi-master asynchronous replication feature, you can use links to interconnect a collection of these catalog service domains and then synchronize the catalog service domains, using replication over the links. Such a topology includes the following advantages:
- Availability and partition tolerance.
- WXS uses a arbitrator to resolve collisions.
- Replication is not queue based. There is no concern if the link is down.
- Each container JVM communicates directly to the shards in the other location.
- Lower response time for user queries.
In a distributed environment, especially those that span data centers across a LAN and WAN, management of client response time is a challenge. As shown in Figure 3-14, response time for the client accessing data from a data center located in a separate geographic region can vary greatly as compared to accessing data from a data center located in its own geographic region. In a multi-master topology, every domain can have its own primary replica. Every domain asynchronously replicates data with its linked domains. Data written to one primary is asychronously replicated to linked primaries as well. This data can be read locally from any data center.
