WebSphere eXtreme Scale overview
WebSphere eXtreme Scale is an elastic, scalable, in-memory data grid. The data grid dynamically caches, partitions, replicates, and manages application data and business logic across multiple servers. WXS performs massive volumes of transaction processing with high efficiency and linear scalability.
With WXS, you can also get qualities of service such as...
- transactional integrity
- high availability
- predictable response times
Use WXS as...
- a very powerful cache
- as an in-memory database processing space to manage application state
- Build Extreme Transaction Processing (XTP) applications
Elastic scalability
Elastic scalability is possible through the use of distributed object caching. With elastic scalability, the data grid monitors and manages itself. The data grid can add or remove servers from the topology, which increases or decreases memory, network throughput, and processing capacity as needed. When a scale-out process is initiated, capacity is added to the data grid while it is running without requiring a restart. Conversely, a scale-in process immediately removes capacity. The data grid is also self-healing by automatically recovering from failures.
WXS versus an in-memory database
WXS cannot be considered an actual in-memory database. An in-memory database is too simple to handle some of the complexities that WXS can manage. If an in-memory database has a server that fails, it cannot repair the issue. A failure can be disastrous if the entire environment is on that one server.
To tackle the problem of this type of failure, eXtreme Scale splits the given data set into partitions, which are equivalent to constrained tree schemas that describe the relationship between entities. When you are using partitions, the entity relationships must model a tree data structure. In this structure, the head of the tree is the root entity and is the only entity that is partitioned.
All other children of the root entity are stored in the same partition as the root entity. Each partition exists as a primary copy, or shard. A partition also contains replica shards for backing up the data.
An in-memory database cannot provide this function because it is not structured and dynamic in this way. With an in-memory database, implement the operations that WXS does automatically.
You can run SQL operations on in-memory databases, improving the processing speed compared to databases that are not in memory. WXS has its own query language instead of SQL support. This query language is more elastic, enables partitioning of data, and provides dependable failure recovery.
WXS with databases
With the write-behind cache feature, WXS can serve as a front-end cache for a database. By using this front-end cache, throughput increases while reducing database load and contention. WXS provides predictable scaling in and scaling out at predictable processing cost.
The following image shows that in a distributed, coherent cache environment, the eXtreme Scale clients send and receive data from the data grid. The data grid can be automatically synchronized with a backend data store. The cache is coherent because all of the clients see the same data in the cache. Each piece of data is stored on exactly one writable server in the cache. Having one copy of each piece of data prevents wasteful copies of records that might contain different versions of the data. A coherent cache holds more data as more servers are added to the data grid, and scales linearly as the data grid grows in size. The data can also be optionally replicated for additional fault tolerance.
Figure 1. High-level topology
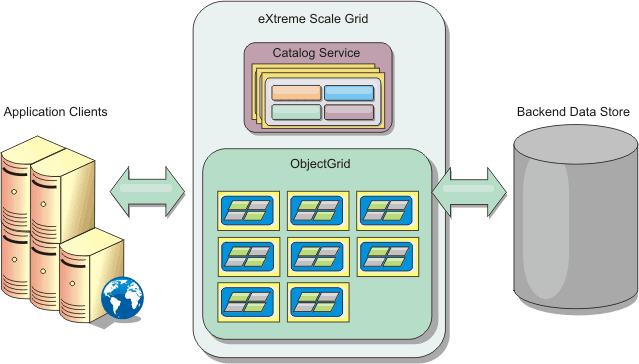
WXS has servers, called container servers, that provide its in-memory data grid. These servers can run inside WAS, or on simple Java™ Standard Edition (J2SE) JVMs. More than one container server can run on a single physical server. As a result, the in-memory data grid can be large. The data grid is not limited by, and does not have an impact on, the memory or address space of the application or the application server. The memory can be the sum of the memory of several hundred, or thousand, JVMs, running on many different physical servers.
As an in-memory database processing space, WXS can be backed by disk, database, or both.
While eXtreme Scale provides several Java APIs, many use cases require no user programming, just configuration and deployment in the WebSphere infrastructure.
Data grid overview
The fundamental data grid paradigm is a key-value pair, where the data grid stores values (Java objects), with an associated key (another Java object). The key is later used to retrieve the value. In eXtreme Scale, a map consists of entries of such key-value pairs.
WXS offers a number of data grid configurations, from a single, simple local cache, to a large distributed cache, using multiple JVMs or servers.
In addition to storing simple Java objects, you can store objects with relationships. Use a query language that is like SQL, with SELECT … FROM … WHERE statements to retrieve these objects. For example, an order object might have a customer object and multiple item objects associated with it. WXS supports one-to-one, one-to-many, many-to-one, and many-to-many relationships.
WXS also supports an EntityManager programming interface for storing entities in the cache. This programming interface is like entities in Java Enterprise Edition. Entity relationships can be automatically discovered from an entity descriptor XML file or annotations in the Java classes. You can retrieve an entity from the cache by primary key using the find method on the EntityManager interface. Entities can be persisted to or removed from the data grid within a transaction boundary.
Consider a distributed example where the key is a simple alphabetic name. The cache might be split into four partitions by key: partition 1 for keys starting with A-E, partition 2 for keys starting with F-L, and so on. For availability, a partition has a primary shard and a replica shard. Changes to the cache data are made to the primary shard, and replicated to the replica shard. You configure the number of servers that contain the data grid data, and eXtreme Scale distributes the data into shards over these server instances. For availability, replica shards are placed in separate physical servers from primary shards.
WXS uses a catalog service to locate the primary shard for each key. It handles moving shards among eXtreme Scale servers when the physical servers fail and later recover. For example, if the server containing a replica shard fails, eXtreme Scale allocates a new replica shard. If a server containing a primary shard fails, the replica shard is promoted to be the primary shard. As before, a new replica shard is constructed.
The simplest eXtreme Scale programming interface is the ObjectMap interface, which is a simple map interface that includes: a map.put(key,value) method to put a value in the cache, and a map.get(key) method to later retrieve the value.
See also
- New and deprecated features in this release
- WXS major concepts
- Plan overview
- Integrate with WebSphere products
- Product name changes
- Directory conventions
- Free trial
- Program and Administration Guides
Related concepts
Product Overview
Cache overview
Cache integration overview
Scalability overview
Availability overview
Transaction processing overview
Security overview
REST data services overview
Spring framework
Tutorials, examples, and samplesRelated information
Glossary
Site map Principles and best practices for building high performing and highly resilient WXS applications
Principles and best practices for building high performing and highly resilient WXS applications