|
| |
|
|
Database integration: Write-behind, in-line, and side caching
WebSphere eXtreme Scale is used to front a traditional database and eliminate read activity that is normally pushed to the database. A coherent cache can be used with an application directly or indirectly using an object relational mapper. The coherent cache can then offload the database or backend from reads. In a slightly more complex scenario, such as transactional access to a data set where only some of the data requires traditional persistence guarantees, filtering can be used to offload even write transactions.
You can configure eXtreme Scale to function as a highly flexible in-memory database processing space. However, eXtreme Scale is not an object relational mapper (ORM). It does not know where the data in eXtreme Scale came from. An application or an ORM can place data in an eXtreme Scale server. It is the responsibility of the source of the data to make sure that it stays consistent with the database where data originated. This means eXtreme Scale cannot invalidate data that is pulled from a database automatically. The application or mapper must provide this function and manage the data stored in eXtreme Scale.
Figure 1. ObjectGrid as a database buffer
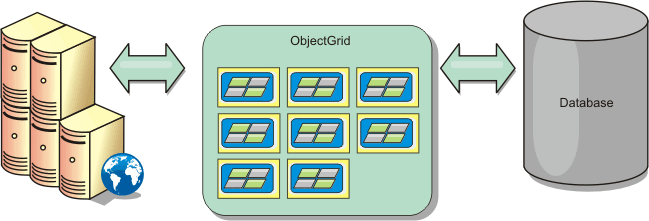
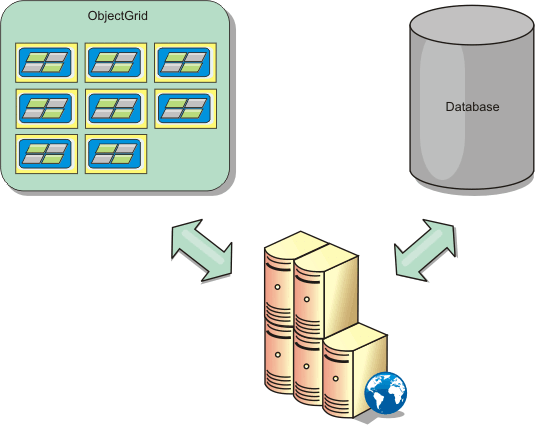
Figure 2. ObjectGrid as a side cache
- Sparse and complete cache
WebSphere eXtreme Scale can be used as a sparse cache or a complete cache. A sparse cache only keeps a subset of the total data, while a complete cache keeps all of the data. and can be populated lazily, on-demand. Sparse caches are normally accessed using keys (instead of indexes or queries) since the data is only partially available. - Side cache and in-line cache
WebSphere eXtreme Scale is used to provide in-line caching for a database back-end or as a side cache for a database. In-line caching uses eXtreme Scale as the primary means for interacting with the data. When eXtreme Scale is used as a side cache, the back-end is used in conjunction with the eXtreme Scale. - In-line caching
In-line caching uses eXtreme Scale as the primary means for interacting with the data. When eXtreme Scale is used as an in-line cache, the application interacts with the backend using a Loader plug-in. - Write-behind caching
Use write-behind caching to reduce the overhead that occurs when updating a database you are using as a back end. - Loaders
With an eXtreme Scale Loader plug-in, an eXtreme Scale map can behave as a memory cache for data that is typically kept in a persistent store on either the same system or another system. Typically, a database or file system is used as the persistent store. A remote JVM (JVM) can also be used as the source of data, allowing hub-based caches to be built using eXtreme Scale. A loader has the logic for reading and writing data to and from a persistent store. - Data pre-loading and warm-up
In many scenarios that incorporate the use of a loader, you can prepare the data grid by pre-loading it with data. - Map preloading
Maps can be associated with Loaders. A loader is used to fetch objects when they cannot be found in the map (a cache miss) and also to write changes to a back-end when a transaction commits. Loaders can also be used for preloading data into a map. The preloadMap method of the Loader interface is called on each map when its corresponding partition in the MapSet becomes a primary. The preloadMap method is not called on replicas. It attempts to load all the intended referenced data from the back-end into the map using the provided session. The relevant map is identified by the BackingMap argument that is passed to the preloadMap method. - Database synchronization techniques
When WebSphere eXtreme Scale is used as a cache, applications must be written to tolerate stale data if the database can be updated independently from an eXtreme Scale transaction.To serve as a synchronized in-memory database processing space, eXtreme Scale provides several ways of keeping the cache updated.
- Invalidate stale cache data
To reduce the window of time when clients may see stale data, you can use an event-based or programmatic invalidation mechanism. - Indexing
Use the MapIndexPlugin to build an index or several indexes on a BackingMap to support non-key data access.
Parent topic:
Cache overview
Related concepts
Cache architecture: Maps, containers, clients, and catalogs