Network Deployment (Distributed operating systems), v8.0 > Monitor > Monitor application flow
Why use request metrics?
Request metrics is a tool that enables you to track individual transactions, recording the processing time in each of the major WAS components. The information that is tracked by request metrics might either be saved to log files for later retrieval and analysis, be sent to Application Response Measurement (ARM) agents, or both.
As a transaction flows through the system, request metrics includes additional information so that the log records from each component can be correlated, building up a complete picture of that transaction. The result looks similar to the following example:
HTTP request/trade/scenario ------------------------------> 172 ms
Servlet/trade/scenario -----------------------------> 130 ms
EJB TradeEJB.getAccountData ---------------------> 38 ms
JDBC select --------------------------------> 7 ms
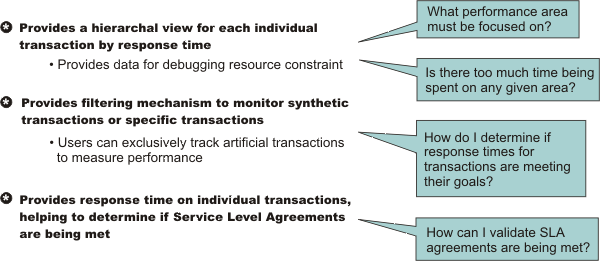
This transaction flow with associated response times can help you target performance problem areas and debug resource constraint problems. For example, the flow can help determine if a transaction spends most of its time in the web server plug-in, the web container, the EJB container or the back end database. The response time that is collected for each level includes the time spent at that level and the time spent in the lower levels. For example, the response time for the servlet, which is 130 milliseconds, also includes 38 milliseconds from the enterprise beans and Java Database Connectivity. Therefore, 92 ms can be attributed to the servlet process.
Request metrics tracks the response time for a particular transaction. Because request metrics tracks individual transactions, using it imposes some performance implications on the system. However, this function can be mitigated by the use of the request filtering capabilities.
For example, tools can inject synthetic transactions. Request metrics can then track the response time within the WAS environment for those transactions. A synthetic transaction is one that is injected into the system by administrators to take a proactive approach to testing the performance of the system. This information helps administrators tune the performance of the website and take corrective actions. Therefore, the information provided by request metrics might be used as an alert mechanism to detect when the performance of a particular request type goes beyond acceptable thresholds. The filtering mechanism within request metrics might be used to focus on the specific synthetic transactions and can help optimize performance in this scenario.
When we have the isolated problem areas, use request metrics filtering mechanism to focus specifically on those areas. For example, when we have an isolated problem in a particular servlet or EJB method, use the uniform resource identifier (URI) algorithms or EJB filter to enable the instrumentation only for the servlet or EJB method. This filtering mechanism supports a more focused performance analysis.
Five types of filters are supported:
- Source IP filter
- URI filter
- EJB method name filter
- JMS parameters filter
- Web services parameters filter
When filtering is enabled, only requests that match the filter generate request metrics data, create log records, call the ARM interfaces, or all. We can inject the work into a running system (specifically to generate trace information) to evaluate the performance of specific types of requests in the context of a normal load, ignoring requests from other sources that might be hitting the system.
Filters are only applicable where the request first enters WAS.
Procedure
- Learn more about request metrics by reviewing detailed
explanations in this section.
- Configure and enable request metrics.
- Retrieve performance data and monitor application flow.
- Extend monitoring to track applications that might require
additional instrumentation points.
Example
Learn how to use request metrics by viewing the following example.
In this example, the HitCount servlet
and the Increment enterprise bean are deployed
on two different application server processes. As shown in the following diagram, the web container tier and EJB container tiers are running in two different application servers.
To set up such a configuration, install WAS ND.
Assume that the web server and the web container tier both run on machine 192.168.0.1, and the EJB container tier runs on a second machine 192.168.0.2. The client requests might be sent from a different machine; 192.168.0.3, for example, or other machines.
To illustrate the use of source IP filtering, one source IP filter (192.168.0.3) is defined and enabled. We can trace requests that originate from machine 192.168.0.3 through http://192.168.0.1/hitcount?selection=EJB&lookup=GBL&trans=CMT. However, requests that originate from any other machines are not traced because the source IP address is not in the filter list.
By only creating a source IP filter, any requests from that source IP address are effectively traced. This tool is effective for locating performance problems with systems under load. If the normal load originates from other IP addresses, then its requests are not traced. By using the defined source IP address to generate requests, you can see performance bottlenecks at the various hops by comparing the trace records of the loaded system to trace records from a non-loaded run. This ability helps focus tuning efforts to the correct node and process within a complex deployment environment.
Make sure that request metrics is enabled using the admin console. Also, make sure that the trace level is set to at least hops (writing request traces at process boundaries). Using the configuration previously listed, send a http://192.168.0.1/hitcount?selection=EJB&lookup=GBL&trans=CMT through the HitCount servlet from machine 192.168.0.3.
In this example, at least three trace records are generated:
- A trace record for the web server plug-in is displayed in the plug-in log file (default location is (
plugins_root/logs/web_server_name
http_plugin.log ) on machine 192.168.0.1.
- A trace record for the servlet displays in the application server log file (default location is $PROFILE_ROOT/logs/appserver/SystemOut.log) on machine 192.168.0.1.
- A trace record for the increment bean method invocation displays in the application server log file (default location is
$PROFILE_ROOT/logs/appserver/SystemOut.log)
on machine 192.168.0.2.
New feature: Beginning in WAS v8.0 you can configure the server to use the HPEL log and trace infrastructure instead of using SystemOut.log , SystemErr.log, trace.log, and activity.log files or native z/OS logging facilities. If you are using HPEL, you can access all of your log and trace information using the LogViewer command-line tool from your server profile bin directory. See the information about using HPEL to troubleshoot applications for more information on using HPEL.New feature:
The two trace records that are displayed on machine 192.168.0.1 are similar to the following example:
PLUGIN: parent:ver=1,ip=192.168.0.1,time=1016556185102,pid=796,reqid=40,event=0 - current:ver=1,ip=192.168.0.1,time=1016556185102,pid=796,reqid=40,event=1 type=HTTP detail=/hitcount elapsed=90 bytesIn=0 bytesOut=2252 Application server (web container tier) PMRM0003I: parent:ver=1,ip=192.168.0.1,time=1016556185102,pid=796,reqid=40,event=0 - current:ver=1,ip=192.168.0.1,time=1016556186102,pid=884,reqid=40,event=1 type=URI detail=/hitcount elapsed=60
The trace record that is displayed on machine 192.168.0.2 is similar to the following example:
PMRM0003I: parent:ver=1,ip=192.168.0.1,time=1016556186102,pid=884,reqid=40,event=1 - current:ver=1,ip=192.168.0.2,time=1016556190505,pid=9321,reqid=40,event=1 type=EJB detail=com.ibm.defaultapplication.Increment.increment elapsed=40
Data you can collect with request metrics
Monitor application flow
Use HPEL to troubleshoot applications