Plan highly available persistent storage
Choosing a storage solution
Before we can decide what type of storage is the right solution for the Red Hat OpenShift on IBM Cloud clusters, we must understand the IBM Cloud infrastructure provider, the app requirements, the type of data that we want to store, and how often we want to access this data.
-
Decide whether your data must be permanently stored, or if your data can be removed at any time.
- Persistent storage: Your data must still be available, even if the container, the worker node, or the cluster is removed. Use persistent storage in the following scenarios:
- Stateful apps
- Core business data
- Data that must be available due to legal requirements, such as a defined retention period
- Auditing
- Data that must be accessed and shared across app instances
- Non-persistent storage: Your data can be removed when the container, the worker node, or the cluster is removed. Non-persistent storage is typically used for logging information, such as system logs or container logs, development testing, or when we want to access data from the host's file system. To find an overview of available non-persistent storage options, see Comparison of non-persistent storage options.
- Persistent storage: Your data must still be available, even if the container, the worker node, or the cluster is removed. Use persistent storage in the following scenarios:
-
If we must persist your data, analyze if the app requires a specific type of storage. When you use an existing app, the app might be designed to store data in one of the following ways:
- In a file system: The data can be stored as a file in a directory. For example, you could store this file on the local hard disk. Some apps require data to be stored in a specific file system, such as nfs or ext4 to optimize the data store and achieve performance goals.
- In a database: The data must be stored in a database that follows a specific schema. Some apps come with a database interface that we can use to store your data. For example, WordPress is optimized to store data in a MySQL database. In these cases, the type of storage is selected for you.
-
If the app does not have a limitation on the type of storage that we must use, determine the type of data that we want to store.
- Structured data: Data that we can store in a relational database where we have a table with columns and rows. Data in tables can be connected by using keys and is usually easy to access due to the pre-defined data model. Examples are phone numbers, account numbers, Social Security numbers, or postal codes.
- Semi-structured data: Data that does not fit into a relational database, but that comes with some organizational properties that we can use to read and analyze this data more easily. Examples are markup language files such as CSV, XML, or JSON.
- Unstructured data: Data that does not follow an organizational pattern and that is so complex that we cannot store it in a relational database with pre-defined data models. To access this data, we need advanced tools and software. Examples are e-mail messages, videos, photos, audio files, presentations, social media data, or web pages.
If we have structured and unstructured data, try to store each data type separately in a storage solution that is designed for this data type. Using an appropriate storage solution for the data type eases up access to your data and gives you the benefits of performance, scalability, durability, and consistency.
-
Analyze how to access your data. Storage solutions are usually designed and optimized to support read or write operations.
- Read-only: You do not want to write or change your data. Your data is read-only.
- Read and write: You want to read, write, and change your data. For data that is read and written, it is important to understand if the operations are read-heavy, write-heavy, or balanced.
-
Determine the frequency that your data is accessed. Understanding the frequency of data access can help you understand the performance that you require for the storage. For example, data that is accessed frequently usually resides on fast storage.
- Hot data: Data that is accessed frequently. Common use cases are web or mobile apps.
- Cool or warm data: Data that is accessed infrequently, such as once a month or less. Common use cases are archives, short-term data retention, or disaster recovery.
- Cold data: Data that is rarely accessed, if at all. Common use cases are archives, long-term backups, historical data.
- Frozen data: Data that is not accessed and that we need to keep due to legal reasons.
If we cannot predict the frequency or the frequency does not follow a strict pattern, determine whether the workloads are read-heavy, write-heavy, or balanced. Then, look at the storage option that fits the workload and investigate what storage tier gives you the flexibility that we need. For example, IBM Cloud Object Storage provides a flex storage class that considers how frequent data is accessed in a month and takes into account this measurement to optimize your monthly billing.
-
Investigate if your data must be shared across multiple app instances, zones, or regions.
- Access across pods: When you use Kubernetes persistent volumes to access your storage, we can determine the number of pods that can mount the volume at the same time. Some storage solutions, such as block storage, can be accessed by one pod at a time only. With other storage solutions, we can share volume across multiple pods.
- Access across zones and regions: We might require your data to be accessible across zones or regions. Some storage solutions, such as file and block storage, are data center-specific and cannot be shared across zones in a multizone cluster setup.
To make your data accessible across zones or regions, make sure to consult your legal department to verify that your data can be stored in multiple zones or a different country.
-
Understand other storage characteristics that impact your choice.
- Consistency: The guarantee that a read operation returns the latest version of a file. Storage solutions can provide strong consistency when we are guaranteed to always receive the latest version of a file, or eventual consistency when the read operation might not return the latest version. You often find eventual consistency in geographically distributed systems where a write operation first must be replicated across all instances.
- Performance: The time that it takes to complete a read or write operation.
- Durability: The guarantee that a write operation that is committed to your storage survives permanently and does not get corrupted or lost, even if gigabytes or terabytes of data are written to your storage at the same time.
- Resiliency: The ability to recover from an outage and continue operations, even if a hardware or software component failed. For example, your physical storage experiences a power outage, a network outage, or is destroyed during a natural disaster.
- Availability: The ability to provide access to your data, even if a data center or a region is unavailable. Availability for the data is usually achieved by adding redundancy and setting up failover mechanisms.
- Scalability: The ability to extend capacity and customize performance based on your needs.
- Encryption: The masking of data to prevent visibility when data is accessed by an unauthorized user.
-
Review available persistent storage solutions and pick the solution that best fits the app and data requirements.
Comparison of non-persistent storage options
We can use non-persistent storage options if your data is not required to be persistently stored or if we want to unit-test the app components.
The following image shows available non-persistent data storage options in Red Hat OpenShift on IBM Cloud. These options are available for free and standard clusters.

| Characteristics | Inside the container | On the worker node's primary or secondary disk |
|---|---|---|
| Multizone capable | No | No |
| Supported in VPC clusters | Yes | Yes |
| Supported OpenShift versions |
|
|
| Data types | All | All |
| Capacity | Limited to the worker node's available secondary disk. To limit the amount of secondary storage that is consumed by the pod, use resource requests and limits for ephemeral storage  . . |
Limited to the worker node's available space on the primary (hostPath) or secondary disk (emptyDir). To limit the amount of secondary storage that is consumed by the pod, use resource requests and limits
for ephemeral storage . |
| Data access pattern | Read and write operations of any frequency | Read and write operations of any frequency |
| Access | Via the container's local file system |
|
| Performance | High | High with lower latency when you use SSD |
| Consistency | Strong | Strong |
| Resiliency | Low | Low |
| Availability | Specific to the container | Specific to the worker node |
| Scalability | Difficult to extend as limited to the worker node's secondary disk capacity | Difficult to extend as limited to the worker node's primary and secondary disk capacity |
| Durability | Data is lost when the container crashes or is removed. | Data in hostPath or emptyDir volumes is lost when:
In addition, data in an emptyDir volume is removed when:
|
| Common use cases |
|
|
| Non-ideal use cases |
|
|
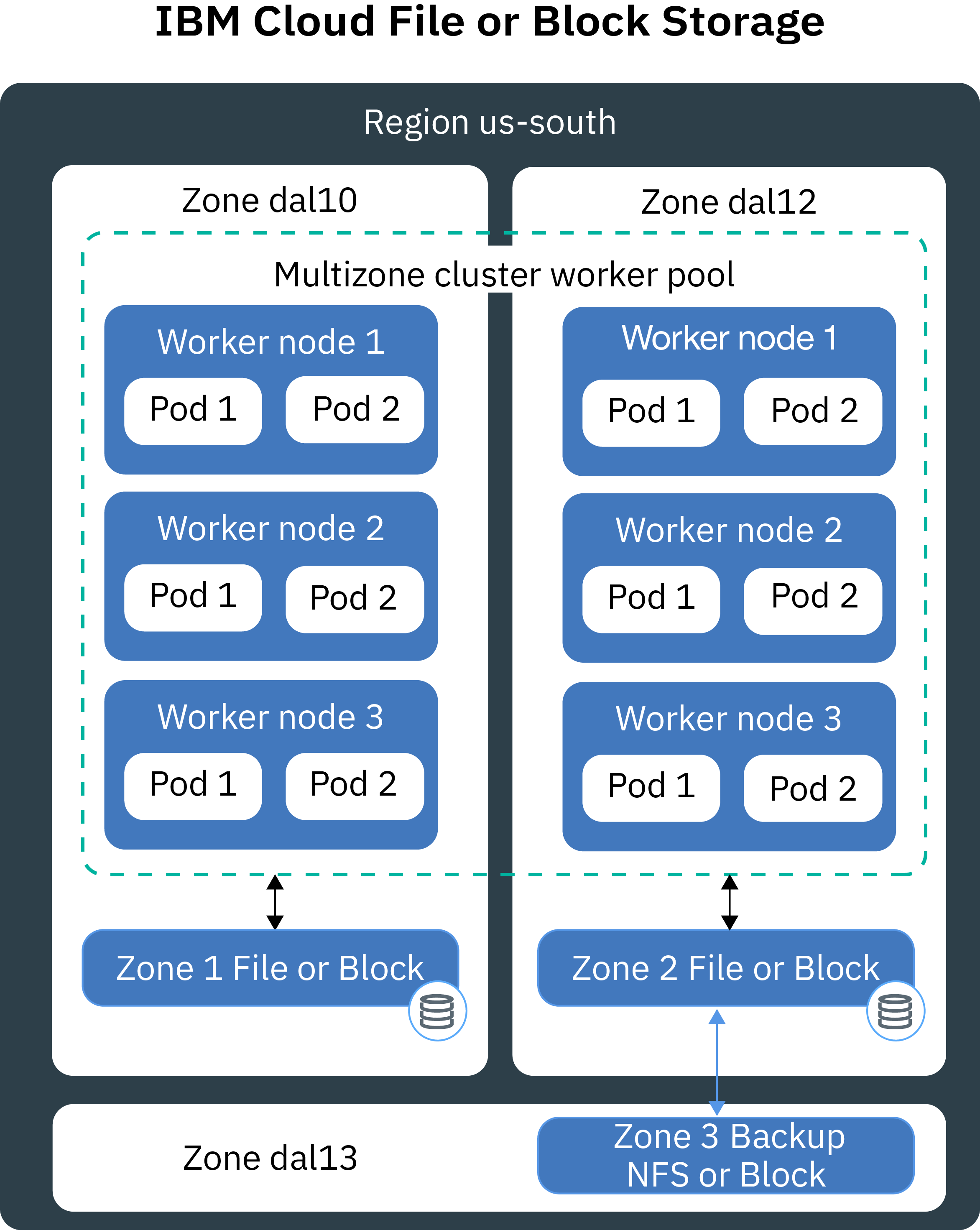
Comparison of persistent storage options for single zone clusters
If we have a single zone cluster, we can choose between the following options in Red Hat OpenShift on IBM Cloud that provide fast access to your data. For higher availability, use a storage option that is designed for geographically distributed data and, if possible for the requirements, create a multizone cluster.Persistent data storage options are available for standard clusters only.
The following image shows the options that we have in Red Hat OpenShift on IBM Cloud to permanently store your data in a single cluster.
| Characteristics | Classic File Storage | Classic Block Storage / VPC Block Storage |
|---|---|---|
| Multizone-capable | No, as specific to a data center. Data cannot be shared across zones, unless you implement your own data replication. | No, as specific to a data center. Data cannot be shared across zones, unless you implement your own data replication. |
| Supported in VPC clusters | No | Yes |
| Supported OpenShift versions |
|
|
| Ideal data types | All | All |
| Data usage pattern |
|
|
| Access | Via file system on mounted volume | Via file system on mounted volume |
| Supported Kubernetes access writes |
|
|
| Performance | Predictable due to assigned IOPS and size. IOPS are shared between the pods that access the volume. | Predictable due to assigned IOPS and size. IOPS are not shared between pods. |
| Consistency | Strong | Strong |
| Durability | High | High |
| Resiliency | Medium as specific to a data center. File storage server is clustered by IBM with redundant networking. | Medium as specific to a data center. Block storage server is clustered by IBM with redundant networking. |
| Availability | Medium as specific to a data center. | Medium as specific to a data center. |
| Scalability | Difficult to extend beyond the data center. We cannot change an existing storage tier. | Difficult to extend beyond the data center. We cannot change an existing storage tier. |
| Encryption | At rest | Classic Block Storage: Encryption at rest. VPC Block Storage: Encryption in transit with Key Protect. |
| Backup and recovery |
|
Classic Block Storage:
VPC Block Storage: Kubernetes oc cp |
| Common use cases |
|
|
| Non-ideal use cases |
|
|
Comparison of persistent storage options for multizone clusters
If we have a multizone cluster, choose between the following persistent storage options to access your data from worker nodes that are spread across zones.Persistent data storage options are available for standard clusters only.
Looking to connect the cluster to an on-prem database instead? See Set up VPN connectivity to the cluster.
The following image shows the options that we have in Red Hat OpenShift on IBM Cloud to permanently store your data in a multizone cluster and make your data highly available. We can use these options in a single zone cluster, but we might not get the high availability benefits that the app requires.
| Characteristics | Object Storage | SDS (Portworx) | IBM Cloud Databases |
|---|---|---|---|
| Multizone-capable | Yes | Yes | Yes |
| Supported in VPC clusters | Yes | Yes | Yes |
| Supported OpenShift versions |
|
|
|
| Ideal data types | Semi-structured and unstructured data | All | Depends on the DBaaS |
| Data usage pattern |
|
|
|
| Access | Via file system on mounted volume (plug-in) or via REST API from the app | Via file system on mounted volume or NFS client access to the volume | Via REST API from the app |
| Supported Kubernetes access writes |
|
All |
|
| Performance | High for read operations. Predictable due to assigned IOPS and size when you use non-SDS machines. |
|
High if deployed to the same data center as the app. |
| Consistency | Eventual | Strong | Depends on the DBaaS |
| Durability | Very high as data slices are dispersed across a cluster of storage nodes. Every node stores only a part of the data. | Very high as three copies of our data are maintained at all times. | High |
| Resiliency | High as data slices are dispersed across three zones or regions. Medium, when set up in a single zone only. | High when set up with replication across three zones. Medium, when you store data in a single zone only. | Depends on the DBaaS and your setup. |
| Availability | High due to the distribution across zones or regions. | High when you replicate data across three worker nodes in different zones. | High if you set up multiple instances. |
| Scalability | Scales automatically | Increase volume capacity by resizing the volume. To increase overall storage layer capacity, we must add worker nodes or remote block storage. Both scenarios require monitoring of capacity by the user. | Scales automatically |
| Encryption | In transit and at rest | Bring your own key to protect your data in transit and at rest with IBM Key Protect. | At rest |
| Backup and recovery | Data is automatically replicated across multiple nodes for high durability. For more information, see the SLA in the IBM Cloud Object Storage service terms .
We can also use the Kubernetes oc cp command to copy data
to and from pod and containers. |
Use local or cloud snapshots to save the current state of a volume. For more information, see Create and use local snapshots .
We can also use the Kubernetes oc cp command to copy data
to and from pod and containers. |
Depends on the DBaaS |
| Common use cases |
|
|
|
| Non-ideal use cases |
|
N/A |
|