![]()
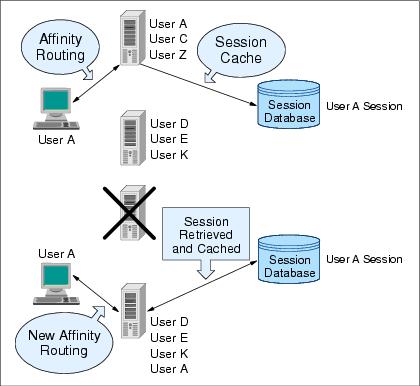
10.7.1 Session affinity and failoverServer clusters provide a solution for failure of an appserver. Sessions created by cluster members in the server cluster share a common persistent session store. Therefore, any cluster member in the server cluster has the ability to see any user's session saved to persistent storage. If one of the cluster members fail, the user can continue to use session information from another cluster member in the server cluster. This is known as failover. Failover works regardless of whether the nodes reside on the same machine or several machines.
Figure 10-7 Session affinity and failover
After a failure, WebSphere redirects the user to another cluster member, and the user's session affinity switches to this replacement cluster member. After the initial read from the persistent store, the replacement cluster member places the user's session object in the in-memory cache, assuming the cache has space available for additional entries. The Web server plug-in maintains the cluster member list in order and picks the cluster member next in its list to avoid the breaking of session affinity. From then on, requests for that session go to the selected cluster member. The requests for the session go back to the failed cluster member when the failed cluster member restarts. WebSphere provides session affinity on a best-effort basis. There are narrow windows where session affinity fails. These windows are:
To avoid or limit exposure in this scenario, if your cluster members are expected to crash very seldom and are expected to recover fairly quickly, consider setting the retry timeout to a small value. This narrows the window during which multiple requests being handled by different processes get routed to multiple cluster members.
|
 The servlet engine does not have an appropriate number of threads to handle the user load.
The servlet engine does not have an appropriate number of threads to handle the user load.