5.5.4 WebSphere HAManager
In our previous examples, the HAManager has been configured as default with a single DefaultCoreGroup. This is the scenario where the lowest number JVM ID will act as coordinator to manage recovery of in-flight transactions and take over management of coordination of the core group membership (that is, the views). More complex configurations can be configured, as explained in WAS documentation.
HAManager is in many ways like a Java version of HACMP, in that it maintains its own heartbeats between cluster instances. One of its main roles, beyond the interface to the WAS Transaction Manager, is supporting failover of other Java singletons. For example, message ordering should be retained for Java messages so that a single instance should, unless explicitly configured otherwise for load balancing, exist in a cluster or more exactly, a core group. Startup of JVMs in the core group require the node agent to be available to ensure quorum; otherwise,some services will wait.
So, by default the messaging engine will exist as active on one member in a cluster, with persistent messages persisted to a JDBC compliant database such as DB2 or Oracle, or a shared filesystem, and failover is handled by HAManager to bring up the messaging engine on another node. This is similar to the behavior that would be seen if HACMP was used with WebSphere MQ Server, but it is all controlled within the JVM with Distribution and Consistency Services managing the intracore group communications. This all occurs at the node level, rather than at the instance level.
More detailed information about HAManager is available at the following address:
http://www.ibm.com/developerworks/websphere/techjournal/0509_lee/050 9_lee.html
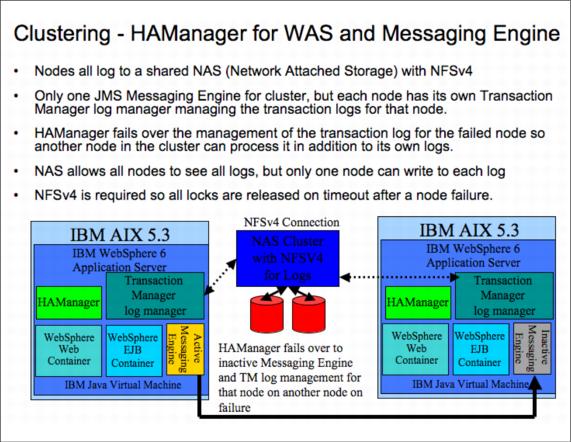
Figure 5-23 HAManager
You may be wondering how HAManager works. It has a number of key components, but you need to understand a few facts about its intent and configuration before delving into its components.
Every instance in a WAS - Network Deployment environment has an HAManager. The HAManager is responsible for managing the singletons primarily, that is, the Transaction Manager of which there is one per instance and the Messaging Engine of which there is one per cluster (to maintain message ordering).
The management of the Transaction Manager requires notifying another instance to take over the transaction management logs, used for XA resource coordination, so they can be processed and apply or roll back any in-doubt transactions.
The management of the Messaging Engine requires another node to take over processing the messages and any persistent storage or database that is associated with it.
To do this all of this, HAManager uses the concept of a core group, of which there is at least one per cell (the DefaultCoreGroup). It is possible to have more than one per cell, and even to bridge between them using the CoreGroupBridge (for example, to cross firewalls isolating cell members). Management of the group membership is handled by the Group Manager component inside HAManager.
Communications between group members must be fast to allow synchronization of data, and for this the Distribution and Consistency Services (DCS) are used. They make use of Reliable Multicast Messaging (RMM) transport and unicast communications. Two inbound DCS TCP transport chains are used; DCS and DCS-Secure, the latter of which supports SSL, and both of which terminate at the DCS_UNICAST_ADDRESS which can be found in serverindex.xml.
This is all part of the DCS services, and essentially consists of control of messages for communication of state updates from group members and heartbeat information, and is more heavily used when memory-to-memory replication of state is enabled.
To receive and hold state information from other members of the core group, a bulletin board function is required, to which messages are sent and interest parties subscribe. This is all handled by the Bulletin Board component inside HAManager.
Overall control of running HAManager is handled by the Agent component. The Agent component maintains a picture of the core group and its state, so it can take remedial action in the event of a failure.
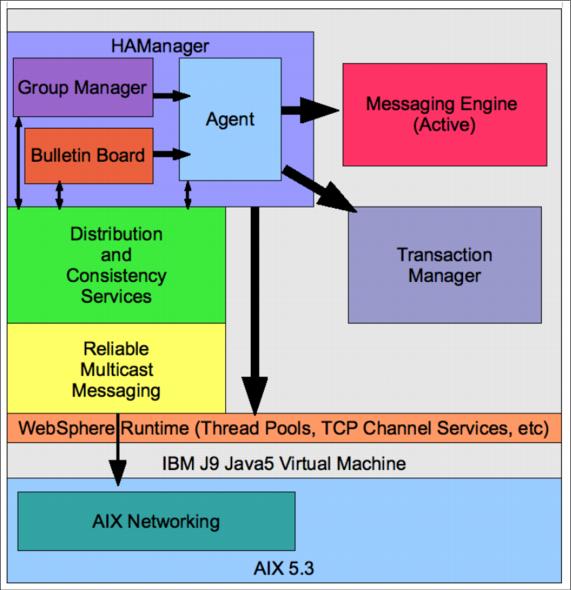
Figure 5-24 HAManager runtime control
When HAManager initializes in a JVM process, it tries to contact the other members of the core group. When it finds another JVM process in the core group, it starts a join process to join that core group. If it is accepted, it becomes one of the instances that receives messages to its bulletin board from other group members, and subscribes to their bulletin board services.
All HAManager instances will then log a message to say the new node has joined. This starts the View Synchrony protocol to ensure that all group members have a synchronized view of the state of the other members, and a similar View Synchrony action is undertaken when an instance stops or its connection drops. Both of these are cases of a view change. In large groups, the HAManager may start to consume significant resources and generate significant network traffic, so breaking the group into smaller groups is advised.
On failure, the JVM with the lowest ID (usually the Deployment Manager, followed by the Node Agent) will take over as coordinator for the group. This behavior can be configured. Overall behavior of the HAManager core group is configured as a policy that is controlled by the Group Manager and applied by the Agent.
So, how should this be managed on AIX? Beware of port conflicts on the DCS_UNICAST_ADDRESS, because it can prevent the instance from starting. Therefore, ensure the nodes are all synchronized from the Deployment Manager if anything changes.
Also be aware that there is a link between the AIX tcp_sendspace, tcp_recvspace, and sb_max settings and the behavior of the DCS unicast and multicast messaging, and a custom setting inside WAS called IBM_CS_SOCKET_BUFFER size may be required for tuning.
The IBM_CS_FD_PERIOD_SECS can be used to change the heartbeat period to additionally change the loading. There are differences in the underlying protocols used between WAS 6.0.0, 6.0.9, and 6.1, so ensure that the appropriate version is configured.
Performance can also be improved by enabling IP address-to-name caching, so set the IBM_CS_IP_REFRESH_MINUTES setting to something appropriate for the given environment. The heap memory used by the replication process can be significant, so tuning for the appropriate size using the IBM_CS_DATASTACK_MEG setting is recommended.
For some WAS versions (6.0.X), the default thread pool was used for HAManager, and overloading caused by errant applications could affect HAManager and its response to the requests on the TCP inbound chain, so configuration to use its own thread pool is recommended.
In general, if the messaging engine is not used and the transactional integrity XA resource coordination is not required, then HAManager can be disabled to increase overall performance of WAS. In general, however, less than 20 core group members should not present significant impact.